【特別企劃】政府資訊開放 除了開放更要好存取易應用
政府資訊開放存取模式 (Dataset)的維護窘境
政府資訊開放(Open Government Data) 雖然只是建構未來成功開放政府(Open Government)的第一步,透過持續地落實資訊開放,始能帶動並催生新穎的開放服務。政府資訊開放原則上盡量保持資料的完整性,但存取模式通常是以資料集(Dataset) 作為存取單位;以資料結構的角度來看,亦可再區分為向量(Vector)、矩陣(Matrix)、陣列(Array)、因素(Factor)、列表(List)、資料框架(Data Frame) 等, 資料元素的模式則亦可區分為整數(Integer)、實數(Numeric)、邏輯(Logical)、複數(Complex)、文字(Character), 以及NA、NaN、INF 等遺失值(Missing Values)。
資料集通常是取樣調查下的結果,或是限制於有限資料集合的靜態資料,如某班級學生成績、機關各項業務承辦人聯絡方式或辦公室位置等—這與資料實體至少具有一個以上自由度(Freedom) 的特性實是相互頇隔的:例如空氣汙染監控資料,自由度在於無止盡的時間軸,只得分割為無數個某某日、某某日等逐漸累增的資料集,當資料集累積到一定量維護工作令人咋舌,開放服務端則更需費工於合併組合與不定時不定量之更新;其他如:固定資產設備、鐵路沿線倉庫出租資訊,將動態異動於新增、修改、刪除於異動活動及地理位置兩種自由度,若加上影像資料,開放資訊將可擴為三個自由度,任一個微小的變動皆需要重新更新資料集,更新週期緩慢時將造成雙方的資訊落差。
 資料實體的動態串流特性
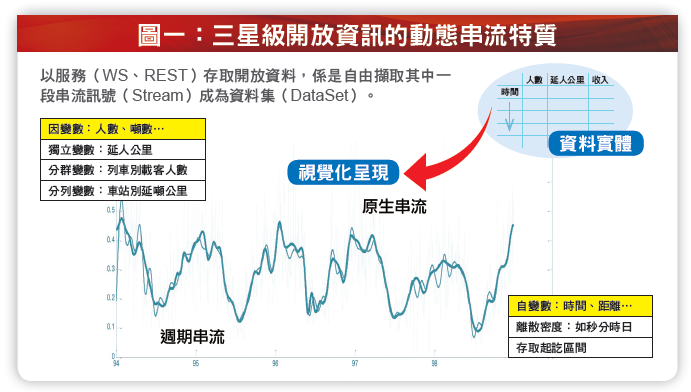
資料實體的動態串流特性
除了少數的詞彙檔、代碼檔、主檔之外,大部分的資料實體皆具有動態串流的特質。如:客運業者營運所產生的簡易營運紀錄檔,為一個自由度的資料實體且其主鍵欄位為時間,當轉換以視覺化呈現便可以看出其為動態串流的特質。動態串流是隨著自變數而變動,並基於串流的離散密度(Discrete Density) 以界定串流資料的間格。開放資訊裡對於原始資料(RowData) 的爭議會在於離散密度的賦予,太密的間格需要昂貴的設備投資,如鐵路業者須添購
各種卡票通行閘門始能獲取精度至秒的原始資料,且開放到每一筆進出旅客紀錄;太疏則可能是人工蒐集統計後輸入系統,其準確度較低且易被質疑為非原始資料。因變數是動態串流主體,可以是獨立變數,如載客人數、延人公里、營運收入等,經分群處理後的各種列車別的載客人數、各種旅客別的載客人數等分群變數,或是明顯分列,如個車站別進出旅客人數等分列變數,較複雜的資料架構則可能需要形成層級架構(Hierarchical Structure) 以分層展列。原生串流(Native Steam) 直接產由系統資料庫,可能具有震盪擺動的特性,經分解降頻週期串流(Periodic Stream) 與事件資料之後將較易於理解其週期性變化,如圖一為原生串流經總體經驗模態分解(EEMD) 與低通過濾(Low-Pass Filtering) 處理後的週期串流。
 修正存取的三星開放等級
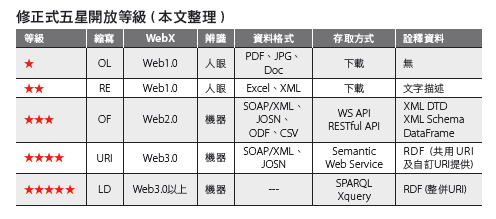
修正存取的三星開放等級
對於動態串流的存取方式則是以服務(WS、REST) API 來存取開放資訊,其係是讓開放服務端自由擷取其中一段串流訊號成為不定量的資料集,此將大幅減省開放服務端合併組合眾多分割資料集與不定時不定量之更新工作,同時亦大幅降低提供端維護超高量資料集的苦難。
W3C 於倡議資訊開放之始即定義五星開放等級, 依序為OL:Open License、RE:MachineReadable、OF:Open Format、URI:Unform Resource Identi er、LD:Linking Data。然而五星開放等級僅是針對開放資訊格式而定義,當再加入機器辨識性以及動態串流之存取方式等因素,可再重新調整界定五星開放等級,如下表。為區隔過往個別資料集下載的存取形式,修正後的三星級開放等級將可擴充為以可收容動態串流並以服務API 存取為主的範疇,其中ODF、CSV 則被限制為資料框架結構之資料格式。
 便捷、有用的開放資訊提供才是王道
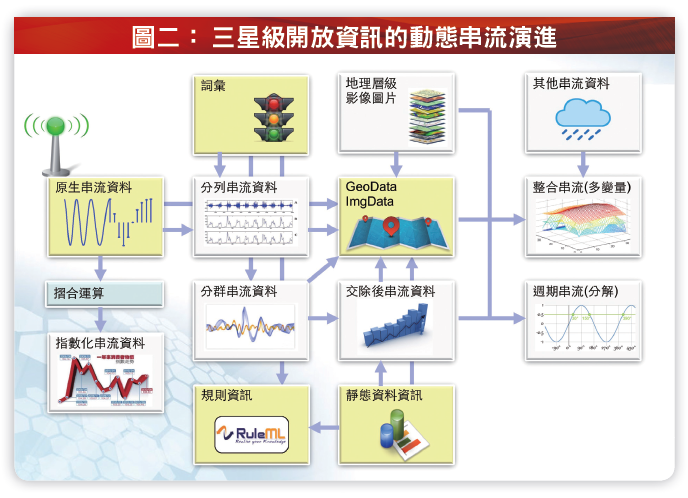
便捷、有用的開放資訊提供才是王道
“資訊”開放翻譯成中文之後,的確比英文原文的“資料”開放要高明許多,因為政府機關已經累積多年使用、整理及分析資料的經驗,便捷、有用的“資訊”提供將提高開放服務端的創新應用效率,而非再由石器時代的“資料”開始摸索起。例如,開放服務端可快速整合捷運站別旅客人數( 分列串流)、歷史氣象資料及車站週邊便利商店銷售紀錄( 形成整合串流),再依據氣象預估機率以備料或進貨,理論上將可增加商品迴轉率並降低滯銷商品成本。分列或分群串流資訊係是由原生串流結合相關辭彙( 如客運車站別) 或基本實體( 如車站間營業里程數) 而成,可再結合地理座標或影像資料形成GeoData 或ImgData。
三星級 資訊開放平台機制
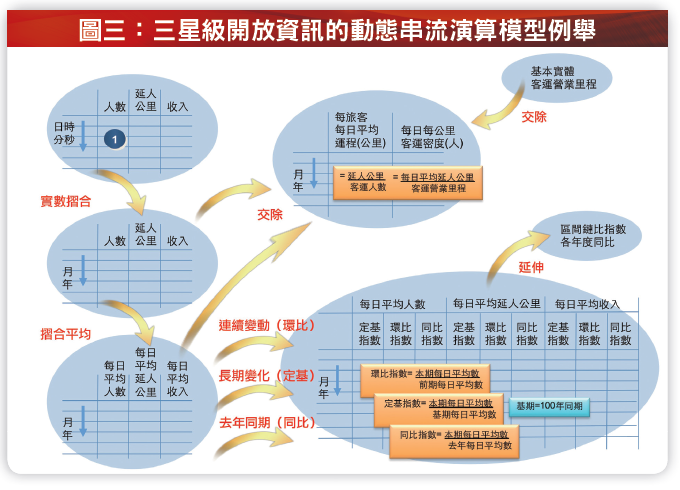
政府資訊開放並非只是掛上一堆數據讓民眾公開下載而已,應善以考量資料活化成資訊以提升運用效益,即是能提供「有用」的資訊,以鼓勵人民、企業參與並合力思考如何彌補公共服務不足,並提出解決方案。基於此,資訊開放平台的規劃更需要考量高度的可存取(Accessibility)、遵循(Compliance)、保密(Confidentiality)、精確(Precision)、可追溯(Traceability)、易理解(Understandability) 及可用性(Availability),以提供精準(Accuracy)、完整(Completeness)、一致(Consistency)、可信賴(Credibility) 及即時更新(Currentness) 的資訊服務。整體三星級資訊開放平台機制將包含:
1. 資料載入及介接轉入
定期或不定期將相關如XML、CSV、Execl 等格式外部檔案或是介接資料庫交換載入或轉入平台的更新資料的資料暫存區。
2. 資料轉置、修補及檢核
為維持資料一致性,資料來源與平台間將依據詞彙對照表對應並自動轉換資料內容,遇中文欄位更需要轉換如「峰」與「峯」、「館」與「舘」之異體字,以及「台」與「臺」、「声」與「聲」之正簡體字。資料修補則是修補NA、NaN、INF 等遺失值或中文自造字產生的,可反覆透過資料檢核功能檢視並增加修補對照表。
3. 資料倉儲與資料管理
平台的核心在於資料倉儲,除了前述之資料更新之資料暫存,包含歷次更新資料之資料暫存區並以動態倉儲架構(Active Data Warehouse)分散佈署數個資料超市(Data Mart) 以提升資訊服務存取效能。管理功能則可包含資料維護、詞彙對照表、修補對照表、相關修補演算、過轉歷史紀錄等。
4. 資訊演算與資訊檢核
資料活化成資訊之演算及視覺化呈現檢核功能,諸如採邏輯集合法(Logical Collection)、邏輯統計區、時序摺合、時段摺合等聚合法(Aggregation) 轉化成前述離散密度恰當之分列、分群或指數化串流,亦可採主成分分析、獨立成分分析、總體經驗模組分解等分解法(Spliting) 重新分層或週期分解串流,必要時則可依據國區、行政區、郵遞區、街區、地址、平面座標等地域資料層級( ematic Data Layer)或空間域資料層級(Spatial Data Layer) 賦予二維或三維座標形成開放地理資訊(GeoData),或給予影像資料形成影像資訊(ImgData)。
5. 服務管理及資訊服務API
資訊服務將可提供前述之靜態資料、動態串流圖四:三星級資訊開放平台示意圖( 以鐵路業者為例之規劃構想)資訊以WS/SOAP、REST/JSON API 作為主要服務介面,並考慮少數瀏覽器能力如IE9 於超過30M 以上時將自動改為下載服務。服務管理將管理相關資訊服務的服務佈署上架、測試、啟動、中止、暖抽換、重啟、請求與授權、下架及汰除等機制。
6. Metadata 管理及Metadata 服務API
為真實對全世界開放而非鎖國造車,將建立及管理MetaData 對重要開放領域之詮釋轉換,包含美國資訊開放專案POD、開放知識基金會CKAN、W3C 資料分類詞彙標準DCAT,以及Google、Microsoft、Yahoo! 等主要搜尋引擎支援的Schema.org 的結構化標示。除了伴隨相關資訊服務同時存取MetaData Schema 服務之外,亦可進一步提供MetaData 分類檢索機制。