資料倉儲與資料湖泊互補 - 巨量資料浪潮衝擊下的思維
巨量資料最常被引用的定義是:「資料量龐大到資料庫系統無法在合理時間內進行儲存、運算、處理,分析成能解讀的資訊。」這個定義是相對的,會隨著年代、產業與專業領域的不同而有所不同。當今許多企業或組織的業務活動相關的資料,無論其種類、產生速度與數量都急遽成長,衍生出巨量資料的4V特色:巨量(Volume)、快速(Velocity)、變異(Variety)、正確(Veracity)。在現今資訊流通快速蓬勃發展的時代,巨量資料帶來效率與生產力等龐大效益已無庸置疑,企業瞭解若能深入分析資料,就能發揮龐大資料潛能,讓決策更迅速、明確與精細,但首先資料管理與分析工具效率必須大幅提升。
回首來時路
線上資料交易處理(OLTP,On-Line Transaction Processing)的關聯式資料庫至今已30 多年,而線上資料分析處理(OLAP)的資料倉儲至今也已20 多年。然而面對巨量資料的挑戰,如:無法有效處理非結構資料、新的資料探索及資料挖掘需求、傳統關聯式資料庫及資料倉儲系統從使用者需求確認、資料模型建立、資料導入及驗證,曠日廢時,並且很多時候在蒐集資料的當下,並不確定資料模型該如何建立,更不用說擴充成本居高不下及受限於垂直擴充架構等等問題。
過去企業從導入資料庫、資料倉儲、發展商業智慧,以面對不斷增長的資料及資料應用問題,隨著時間與科技發展,資料量持續增加、資料類型漸趨複雜,傳統架構將可能不敷使用,也促使大家思考新架構的產生。
2011 年富比士雜誌在「Big Data Requires a Big, New Architecture」一文中提出了資料湖泊這個新架構,如今企業已開始將巨量資料儲存至採用Hadoop 這類技術的資料湖泊,相較於將資料以資料倉儲(Data Warehouse)模式儲存,資料湖泊(Data Lake)被廣泛視為巨量資料快速演進的下一步。
巨量資料
引發了傳統資料倉儲與資料湖泊之爭

還記得1990 年代兩位資料倉儲大師Bill Inmon及Ralph Kimball 所引發的架構與方法論之爭論,即以關聯式資料模型發展的整合式企業資料倉儲架構與以維度資料模型(Dimensional data model) 發展的資料倉儲架構。如今這兩位大師仍在, 然而卻也免不了捲入資料倉儲與資料湖泊的主流技術Hadoop 的戰火中。與Kimball 密切合作的Hadoop 供應商Cloudera 的一段廣告〝CLOUDERA-BIG DATA – Turbocharge your data warehouse〞,挑起Inmon 的反擊之詞〝Turbocharge Your Porsche – Buy An Elephant.〞,這也反映出資料湖泊的概念源自2010 年Pentaho 公司技術長James Dixon 於個人部落格發表的文章《Pentaho, Hadoop, and Data Lakes》。資料湖泊架構有別於傳統的資料倉儲,傳統的資料倉儲的資料通常是品質較高且是被預先處理過的資料;而資料湖泊架構的設計是可擷取大量的、各種類型的資料,作為資料素材的儲存管理,以利分析應用,正因為資料湖泊架構範圍更廣、在資料分析上擁有更多彈性,很適合做為導入巨量資料分析應用的架構藍圖。
資料湖泊資料可包含各式的MPP 資料庫、In-Memory 資料庫及HDFS 分散式儲存資料庫,各種來源、各類型的資料在資料湖泊經由不同方式的儲存、處理、淨化、管理後,有彈性的產出各種分析資料。不同的是,資料湖泊可同時包含「未被清理的資料」(Unclean Data),保持其最原始的形式,故分析者可取得最原始模式的資料,以減少資源上處理數據的必要,讓來自各機關的資料來源更易於結合。
資料湖泊主要有四點特性:以低成本保存巨量資料(Size and Low Cost)、維持資料高度真實性(Fidelity)、資料易取得(Ease of Accessibility)及資料分析富彈性(Flexible)。
資料湖泊的成長模型
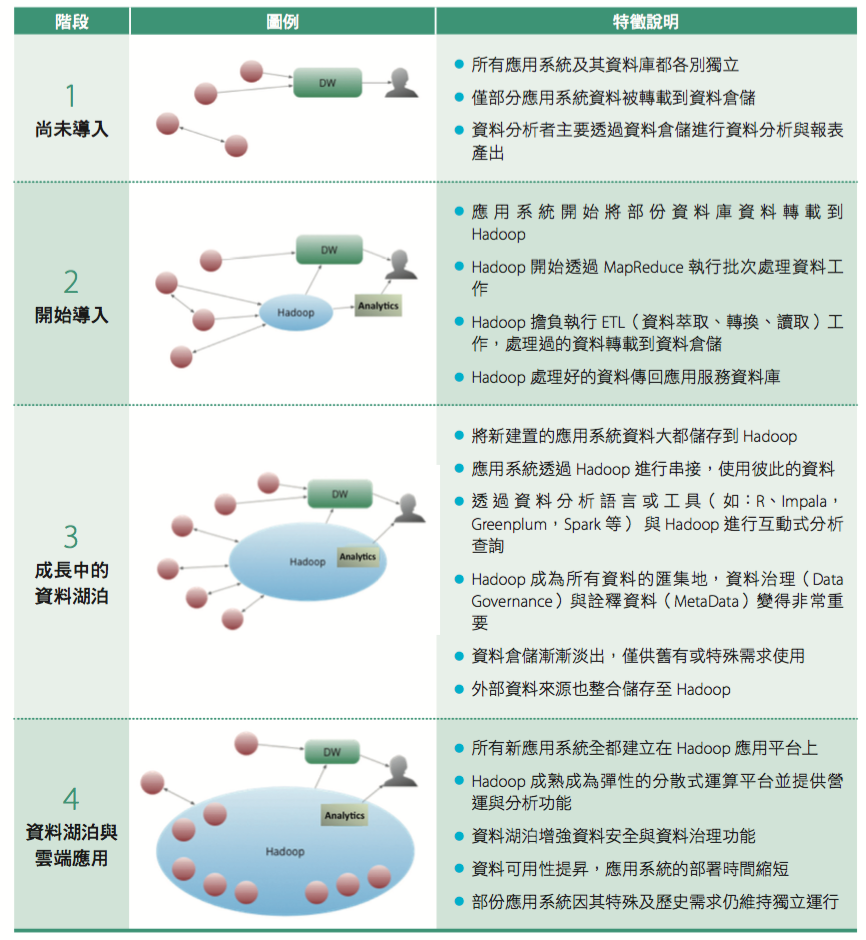
根據2014 年1 月富比士雜誌的「 e Data Lake Dream」一文,提到資料湖泊的發展成熟度可分為四個階段,以幫助瞭解發展資料湖泊發展到極致會達到的狀態,並對比目前的現況屬於哪個階段,如下頁表一。
目前大部分企業仍處於尚未導入時期;有些開始導入Hadoop 的企業則處於剛導入階段;僅少數公司如Google 及Facebook 等因其資料規模大到需要高效率的資料處理架構而發展至最後極致階段。不論現在每個企業身處哪個階段,展望未來,資料湖泊的概念將持續引導企業建構滿足面對巨量資料挑戰的資料處理架構。
攜手向前行─
資料倉儲與資料湖泊互補
姑且不論後續爭論如何,短期內資料倉儲與資料湖泊仍將各有擅長。Cloudera 創始人之一Mike Olson 認為:「新一代資料庫技術,並不會去破壞現有大企業習於使用的 OLTP 及OLAP等結構化資料處理與分析的市場。」現階段大家最關心的議題是兩者是否可以互補,所幸這個議題在業界已逐漸呈現較為一致的思維。
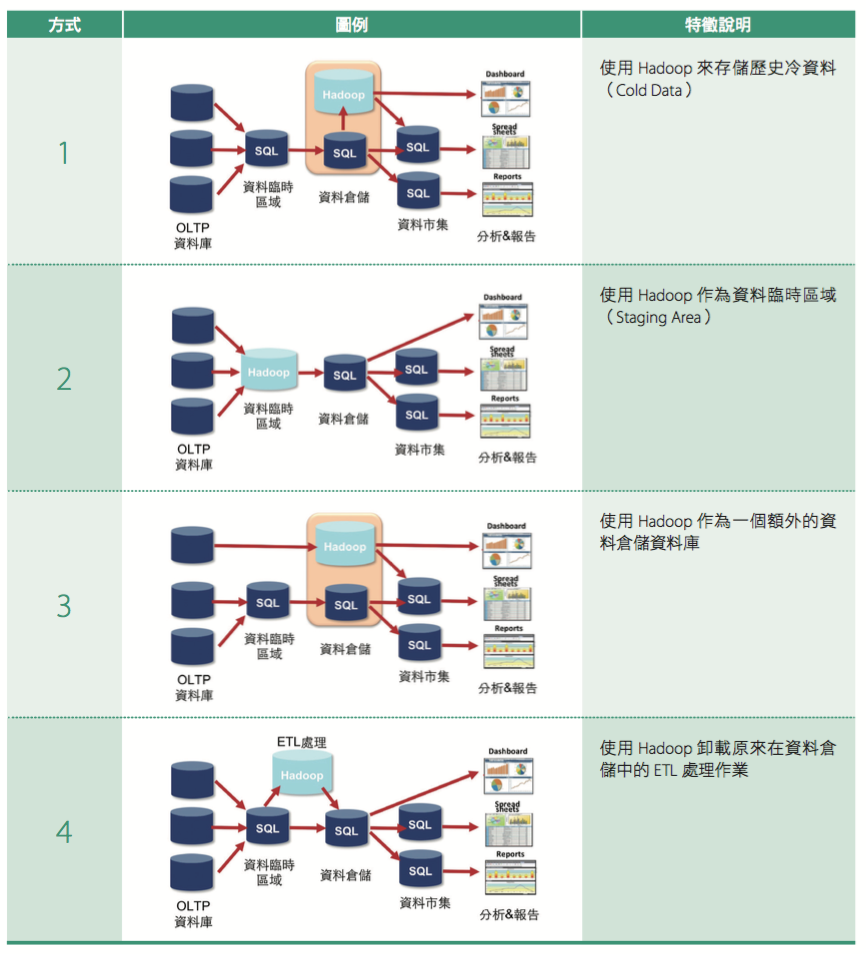
首先對於穩定結構化的資料且需要高效率資料查詢及分析的工作,仍以資料倉儲的方式建置。而對於非結構資料、新的資料探索及資料挖掘需求、不確定資料模型,以及解決擴充成本居高不下及受限於垂直擴充架構等問題,則可以思考Hadoop 在資料倉儲環境中扮演資料倉儲優化的角色,其主要透過如表二中的四種方式來彌補資料倉儲的不足。