如何確保大數據分析的品質:淺談監督式機器學習的測試評估方法
大數據分析與監督式機器學習
隨著科技進步的日益月新,當大數據分析(Big Data Analytics)結合物聯網(Internet of Things,IOT),往往更需要在不確定的動態環境中進行各種自主辨識、過濾、分類、分析、對策,或是自動導航、探勘、移動、警示、通報等等作業。為了能大幅減少人工介入處理的可能,最廣為採用處理這些不確定性的方法即是讓智能機器(Intelligent Machine)能像人類一般地學習並自我認知周遭的世界,此方法被稱為機器學習((Machine Learning)。常見的機器學習類型可以區分為三類,即是監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning),以及增強式學習(Reinforcement Learning)。
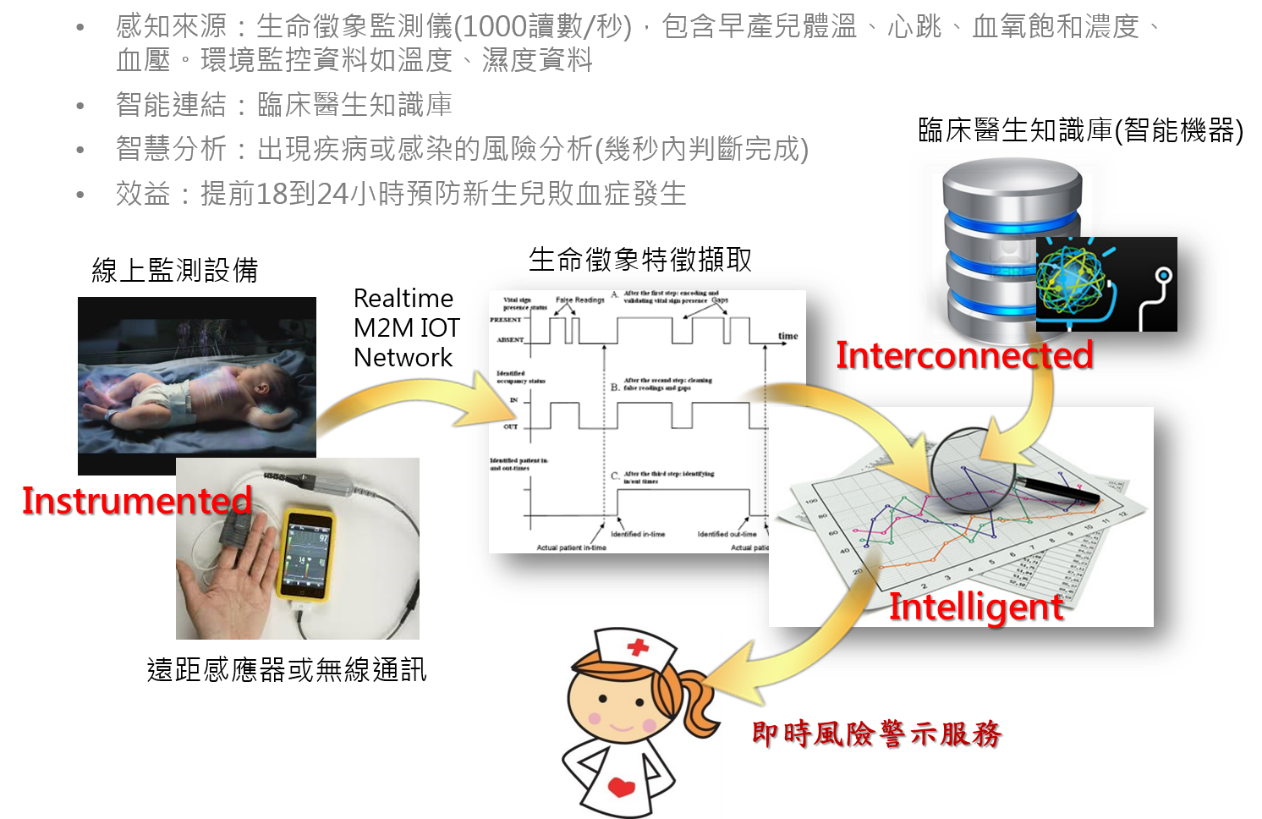
圖一:例舉大數據分析的智能架構(安大略理工的DataBaby風險警示)
其中,監督式機器學習是近幾年來最熱門的類型,其模式是藉由訓練資料讓智能機器可以學到或建立一個模型並據此模型進行實際上的推測。訓練資料是由輸入資料(向量)及預期輸出所組成,而輸出可以是連續值(稱為迴歸分析)或是預測其中一個分類標籤(稱作分類)。常見的技術如人工神經網路(Artificial Neural Network,ANN)、案例推論(Case-Based Reasoning)、決策樹學習(Decision-tree Learning)、最近鄰居法(k-Nearest Neighbor,kNN)、支持向量機(Support VectorMachine,SVM)、支持向量資料描述(Support Vector Data Description,SVDD)等(後兩項如圖二所示)。諸如在工業4.0所揭櫫之智能產品領域中,豐田公司便是利用支持向量機對激流與非激流狀態的資料主成分建立分類模型以作為最佳激流曲線的邊界,並據以形成預測分析工具並整合到空氣壓縮機的控制系統中,使其具有線上激流監控及優化控制能力的智能壓縮機。
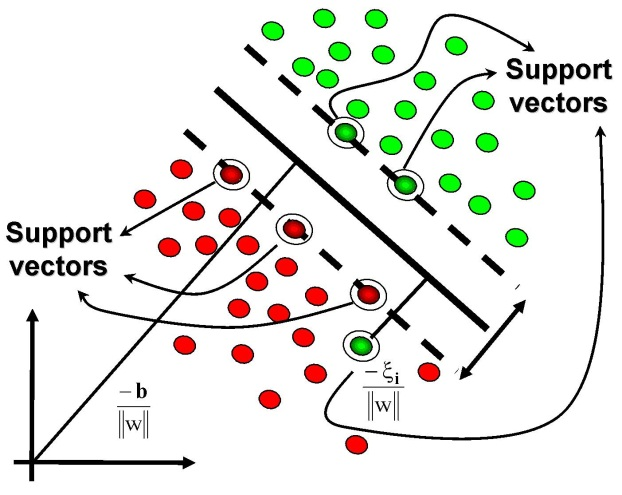
(a) 支持向量機 (b) 支持向量資料描述
圖二:支持向量機及支持向量資料描述(維基百科)
然而因為傳統的軟體測試方法、測試設計技術並無法完成適用於新型的監督式學習型智能機器,因此必須重新學習適應並導入其專屬形式的測試評估方式、度量指標以及圖形化度量。
測試評估法
為了易於理解,下述例舉的各種測試評估法皆是以十二等分的圓餅圖來例舉表示資料集(Dataset)中用來訓練、測試或未使用的比例,其中紅色代表測試資料、藍色為訓練資料,而黃色則代表未使用或尚未使用的部分。唯一的例外是在拔靴確認法中是深藍色則代表重複使用的例子,如此訓練資料的大小便會等同於整個資料集。
- 截留確認法(Holdout Validation)
決定智能機器泛化能力最好的方法是使用未訓練過的資料來評估其效能,截留確認法將資料集分為兩部分,通常是2/3的資料用來訓練,剩下來1/3用來測試。但對於較小的資料集,這種方法經常會先行隨機重複擴展成較大的資料集才開始進行訓練與測試。
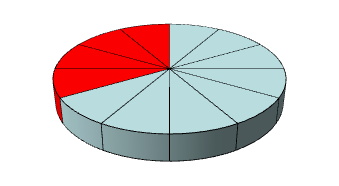
圖三:截留確認法資料集使用於評估之示意(本文整理繪製)
-
換置測試法(Resubstitution)
或可稱為自我一致性測試評估法(Self-Consistency Test Evaluation),是以相同的資料進行訓練及測試。這的測試往往對於真實的泛化誤差有著過於樂觀的估計,因此較少使用於分類器性質的智能機器效能評估上。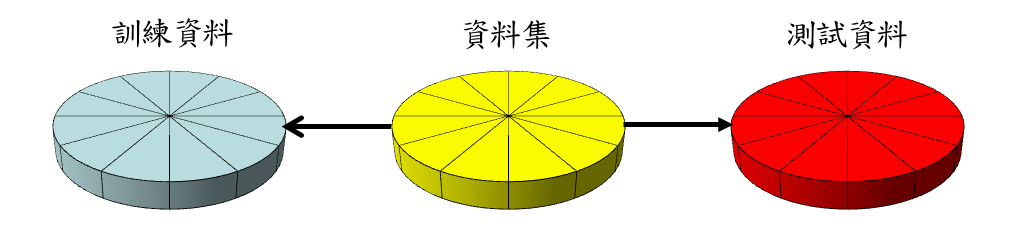
圖四:換置測試法資料集使用於評估之示意(本文整理繪製) -
交叉確認法(Cross Validation)
有時亦稱旋轉評價法(Rotation Estimation),是統計學上將資料樣本切割成數個較小的子集,並先以一個子集訓練並建立模型,而其它子集則用來對此模型進行測試。常見的N折交叉確認(N-Fold Cross Validation)是將資料集分割為N份,其中N-1份用於訓練,保留的一份則用於測試,如此反覆進行使得每一份都被測試過一次。實務上為了獲得有效的信賴區間,通常都是分割為十份,即是10折交叉確認(10-Fold Cross Validation)。另外,最極端的情況就是切割成每一筆資料為一份,則稱為留一交叉確認(Leave-One-Out Cross Validation,LOOCV),留一交叉確認的每一筆資料都會用於訓練及測試,如此重複進行直到每一筆都被訓練及測試為止。
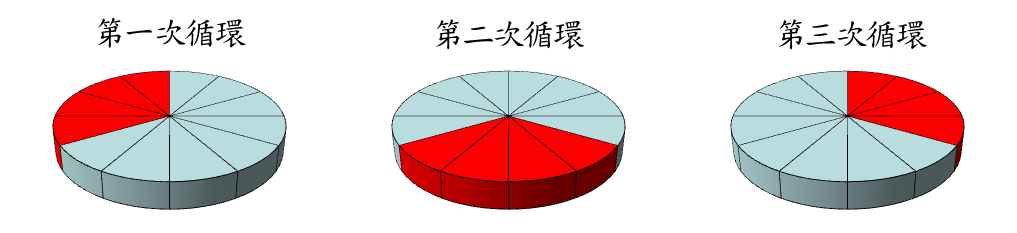
圖五:例舉3折交叉確認法資料集使用於評估之示意(本文整理繪製) -
漸進確認法(Progressive Validation)
漸進確認法是使用資料集分割份數的一半開始進行訓練,然後以其中一份測試。接下來再將測試那份也放進訓練,然後再以另一份未使用過的資料繼續測試,如此漸進進行直到最後一份未使用的資料也進行測試。

圖六:漸進確認法資料集使用於評估之示意(本文整理繪製)
-
拔靴確認法(Bootstrap Validation)
拔靴確認法是自資料集中任意取樣出測試資料並同時產生訓練資料,這個過程會反覆進行許多次。大部分的狀況下,每一回合的過程中取樣的測試資料約佔資料集的1/3,但非定數定量每次可能都不同,亦可以將測試資料放回訓練資料。在某些狀況下拔靴法會優於交叉確認法,但不容易重現過往每次的測試結果。
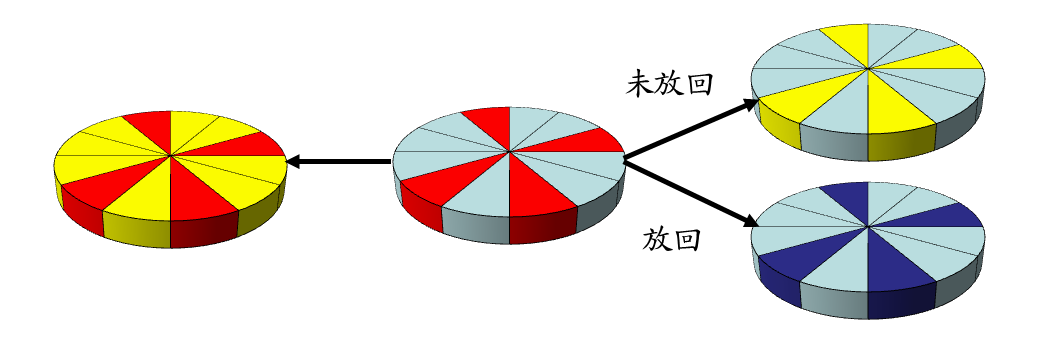
圖七:拔靴確認法資料集使用於評估之示意(本文整理繪製)
度量指標
通常以純量度量指標較容易表列辨識監督式學習型智能機器的成功或失敗項並據以進行繪圖,而且每一個純量度量指標皆有其代表的意涵。以下將臚列在各個應用領域常見的各種純量度量指標:
- 真陽性(True Positive,TP):真實值是陽性且軟體預測輸出結果是陽性,正確
- 真陰性(True Negative,TN):真實值是陰性且軟體預測輸出結果是陰性,正確
- 假陽性(False Positive,FP):真實值是陰性且軟體預測輸出結果是陽性,不正確。代表是對錯誤的誤判並發出假警報,被稱之為第一類錯誤
- 假陰性(False negative,FN):真實值是陽性且軟體預測輸出結果是陰性,不正確。代表是對正確的誤判並未命中,被稱之為第二類錯誤
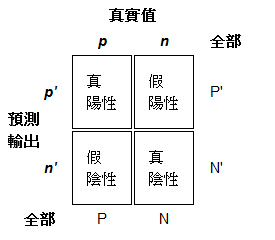
圖八:例舉二元分類的混淆矩陣(維基百科) - 準確度(Accuracy,ACC):代表預測正確的準確度
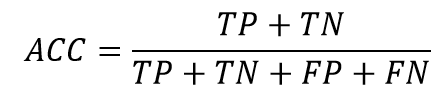
- 靈敏度(Sensitivity,SEN):代表正確預測為陽性的命中率,亦被稱為真陽性率(True Positive Rate,TPR)。在資訊檢索的領域中,真陽性率被稱為求全度(Recall),即是應該被檢索出的文件有多少是檢索出的。
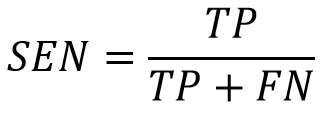
- 特異性(Specificity,SPE):代表正確預測為陰性的命中率,亦被稱為真陰性率(True Negative Rate,TNR)
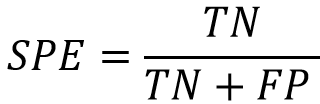
- 陽性預測值(Positive Predictive Value,PPV):代表預測為陽性的正確率。在資訊檢索的領域中,陽性預測值被稱為精準度(Precision),即是所有被檢索出的文件有多少是切題的。
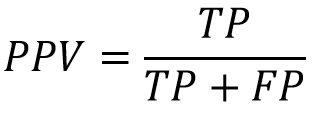
- 陰性預測值(Negative Predictive Value,NPV):代表預測為陰性的正確率
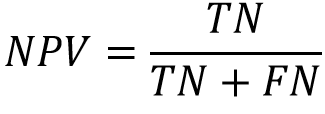
- 假陽性率(False Positive Rate,FPR):代表預測為陽性的錯誤率,第一類錯誤的機率
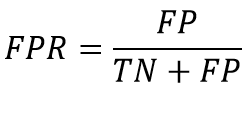
- 升降預測(Lift Predictions,LFT):升降預測時常在行銷領域中被使用,其是度量精準度高的前p%預測,通常都是取前25%
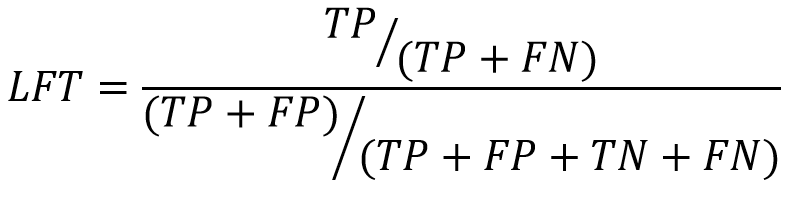
- 皮氏F-分數(Piotroski F-Score ,FSC):在理論上,精準度(Precision)跟求全度(Recall)之間是沒有絕對的對應關係,但在實際應用上,通常精準度會隨著檢索文件越多而遞減,而求全度則會逐漸遞增。F-分數就是精準度與求全度的調和平均數(Harmonic Mean)
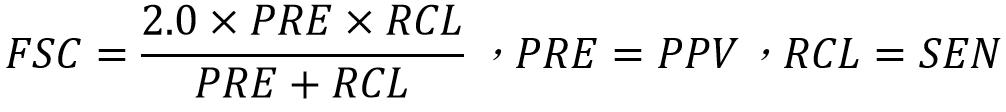
- 馬修相關係數(Matthew's Correlation Coefficient,MCC):馬修相關係數測量預測的準確度。當預測器預測全為正確其值為1;全為錯誤其值為-1;若隨機胡亂猜測則其值為0
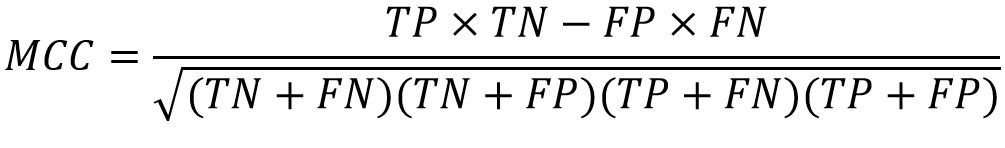
- ROC曲線下面積(Area Under the ROC Curve,AUR):接收者操作特徵(Reciever Operating Characteristic,ROC)空間將FPR和TPR定義為x和y軸,這樣就描述了真陽性和假陽性之間的博弈。而TPR就可以定義為靈敏度,即為獲益;而FPR就定義為1-特異性,即為成本。每一個預測結果在ROC空間中以一個點代表,預測評估後就可以透過歷次的ROC點畫出ROC曲線。ROC曲線越接近於左側及頂端,亦即AUR越大,即代表學習效率越好

- AUP曲線下面積(Area Under the Precision Recall Curve,AUP):被經常使用的資訊檢索任務中的精準求全曲線,在分類分佈上交替形成一個大的傾斜度是最好的。在ROC空間中顯示為最佳化分類器可能未必顯示是最佳的AUP空間
- 盈虧平衡點(Break Even Point,BEP):常用於資訊檢索領域中,盈虧平衡點被定義為精準度及求全度相等時
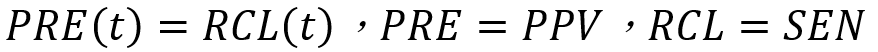
- 成本曲線下面積(Area Under the Cost Curve,AUC):當假設所有可能的機率成本值都是相同時,成本曲線下面積代表分類器的預期成本,AUC值越低越好
- 均方根誤差(Root Mean Squared Error,RMSE):均方根誤差描述說明預測值與目標值相符合有多接近
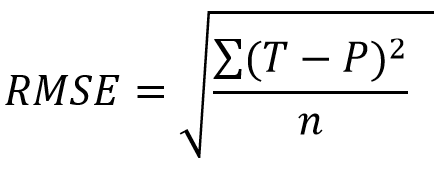
- 平均交叉熵(Mean Cross Entropy,CXE):當假設所有可能的機率介於[0, 1]間,交叉熵則可測量預測值與目標值相符合有多接近。交叉熵再以資料集的大小正規化便形成平均交叉熵。交叉熵為無窮大平均交叉熵的值為0或1
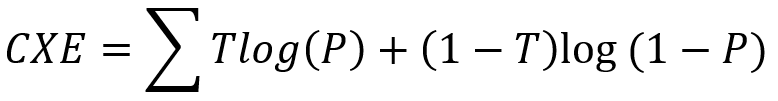
圖形化度量
單一純量純量度量指標往往無法同時指出監督式學習型智能機器的兩類錯誤(即第一類錯誤:假陽性,對錯誤的誤判並發出假警報;第二類錯誤:假陰性,對正確的誤判並未命中),並且在不考慮其他環境下比較分類器之間的優劣。下列幾種常用以生成曲線方式的方法可以解決上述問題,並讓人易於理解。
- ROC曲線圖(ROC Curves):是以x軸的假陽性(1-特異性)及y軸的真陽性(靈敏度)來描述分類器的效能,其中曲線越接近左側和頂端代表分類器越好。
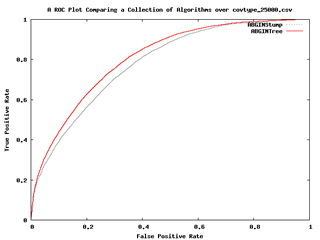
圖九:ROC曲線圖(Malibu操作手冊)
- AUP曲線圖(Precision Recall Curves):是以x軸的求全度及y軸的精準度來描述分類器的效能,在分類分佈上交替形成一個大的傾斜度是最好的。在ROC空間中顯示為最佳化分類器可能未必顯示是最佳的AUP空間。有時也可能看到逆轉型式的型式,便可知是屬於陰性預測,可逆轉預測型式便可得到正確的預測。
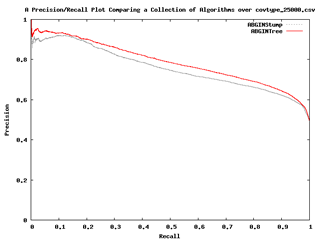
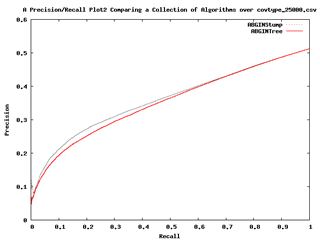
圖十:AUP曲線圖(Malibu操作手冊)
- 成本曲線圖(Cost Curves):是以x軸的全範圍分類分佈及y軸的分類錯誤的預期成本(或錯誤率)來描述分類器的效能,如下圖左圖所示,再由單一的成本線內插ROC空間中的點形成下包絡線,如下圖右圖所示。當分類器是優於其他時,其下包絡線是低於其他分類器的。
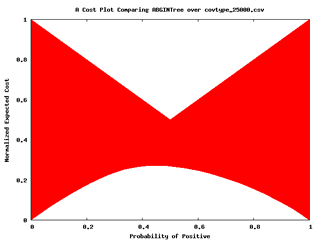
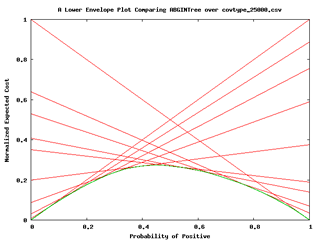
圖十一:成本曲線圖(Malibu操作手冊)
- 升降曲線圖(Lift Curves):是以x軸的預測陽性機率及y軸的升降預測來描述分類器機率估算的效能。
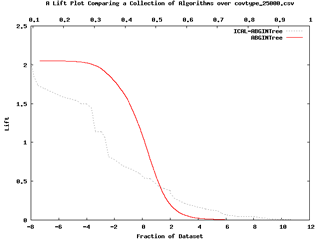
圖十二:升降曲線圖(Malibu操作手冊)
參考資料
S. Kotsiantis, “Supervised Machine Learning: A Review of Classification Techniques”, Informatica Journal 31 (2007): 249-268.
Kohavi, Ron. "A Study of Cross-Validation and Bootstrap for Accuracy Esimation and Model Selection." Paper presented at the International Joint Conference on Artificial Intelligence, Montreal, Canada 1995.
Blum, Avrim, Adam Kalai, and John Langford. "Beating the Hold-Out: Bounds for K-Fold and Progressive Cross-Validation." Paper presented at the Twelfth Annual Conference on Computational Learning Theory Santa Cruz, California 1999.
Efron, Bradley. "Estimating the Error Rate of a Prediction Rule: Improvement on Cross-Validation." Journal of the American Statistical Association 78, no. 382 (1983): 316-31.
Davis, Jesse, and Mark Goadrich. "The Relationship between Precision-Recall and Roc Curves." Paper presented at the 23rd International Conference on Machine learning Pittsburgh, Pennsylvania 2006.
Peterson, W.W., T.G. Birdsall, and W.C. Fox. "The Theory of Signal Detectibility." Transactions of the IRE Professional Group in Information Theory 2, no. 4 (1954): 171-212.
Chris, Drummond, and C. Holte Robert. "Cost Curves: An Improved Method for Visualizing Classifier Performance." Machine Learning V65, no. 1 (2006): 95-130.
Joachims, Thorsten. "Text Categorization with Support Vector Machines: Learning with Many Relevant Features." University Dortmund, 1997.
Matthews, B. W. "Comparison of the Predicted and Observed Secondary Structure of T4 Phage Lysozyme." Biochimica et biophysica acta 405, no. 2 (1975): 442-451.