產業專利知識平台 當群體智慧遇上人工智慧 — 智慧財產局的智慧選擇
為強化科技與智財應用之整合,推展大數據建設,行政院於 2010 年推動智財戰略綱領,到 2014 產業升級轉型行動方案整合全球專利技術資訊,經濟部智慧財產局(以下簡稱智慧局)「專利大數據知識領航計畫」,該計畫由叡揚資訊開發建置產業專利知識平台系統。
智慧局規劃整體平台,主要規劃分四大部份:專利文件轉換機制、專利知識服務平台、專利技術辭庫自動學習及本國專利文獻的自動分類;平台建置採分散式系統,以開放原始碼軟體為主要基礎,同時導入人工智慧(AI)的機器學習方法,作為未來專利知識平台的持續推動的發展方向。叡揚資訊在軟體開發、系統整合的專業,以及在機器學習自然語言方面相當的投入,獲得智慧局的肯定而承接此專案。
巨量專利資料 共通格式轉換
專利知識平台系統處理來自全球五大專利局,包括歐、美、日、韓、中國大陸,加上智慧局的發明專利公開開放格式文件,原本 XMLbase資料轉換為共通格式的JSON文件,為因應每年近200萬大量專利資料的儲存與分析,以 Apache CouchDB 非關聯式文件型資料庫搭配 MySQL 關聯式資料庫,並採用Apache Solr 作為全文檢索引擎,以Solr 及 ZooKeeper 的 SolrCould 方案達成分散式索引系統,提供對外開放、可加值應用之專利文件資料庫。
專利檢索在應用上有侷限性,除需要知道精準詞彙,大量的檢索結果,仍需要仰賴人工過濾才能真正取得需要內容,也看不出主題歸屬。正是希望透過「群體智慧」使用者行為與專利分析的來找出隱含的產業動向,提供接近產業所需要的智慧搜尋。
產業專利知識平台作為專利資料的整合介面,提供專利資訊瀏覽、檢索及資料下載,為了讓使用者可以快速及便利地在大量數據中獲得所需的資訊,是以輕量簡潔開發框架及響應式網頁設計,讓平台功能的整合擴充有較大的彈性。與此同時,智慧局針對專利知識平台基礎服務同時進行訪查國內產業 / 企業、蒐集企業需求及使用意見,以為功能擴增改善之依據,服務能切合企業所需。
除了結合使用者行為,產業專利知識平台將 AI 領域技術,應用在專利技術辭庫自動學習與本國專利文件自動分類系統,龐大的專利文件資料庫,透過機器學習與文字探勘技術進行內容分析,建立高階檢索及知識應用的基礎。叡揚資訊在 2015 年運用機器學習技術在公文自動化分文上已有相當成果,準確度達85%。
在智慧局產業專利知識平台專案開發過程,專案團隊以其經驗,對於更為複雜的專利文件,比較各工具及演算法的優缺點,進行技術測試與驗證,建立作為辭庫分析、自動分類與檢索佈建的專利分析引擎。辭庫分析是以機器學習之詞頻選取演算技術,透過系統程式可針對專利文件進行自動分析作業,定義與記錄其技術關鍵字詞,建立專利分類技術辭庫;自動分類則是以機器學習中的監督式學習建立分類模型,藉由分類模型便可以預測新進文件屬於各分類的機率,以達到自動分類的效果。
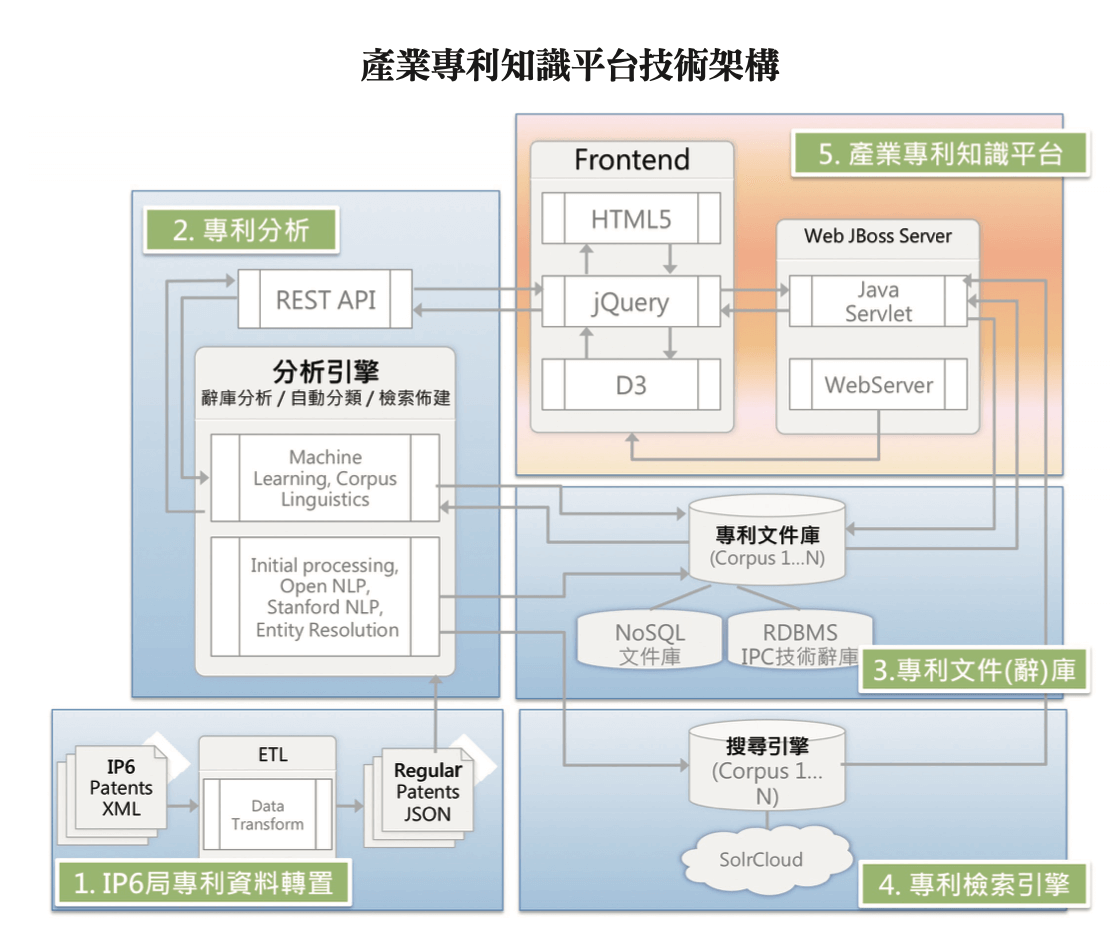
運用自然語言處理、機器學習的專利分析引擎
專利分析引擎的技術辭庫自動學習技術主要是自然語言處理中包括分詞/ 斷詞、標註詞性及關鍵詞抽取的技巧;專利自動分類技術則包括文件前置處理、特徵值處理、分類模型訓練及回饋機制的流程。
因為語言的變化萬千,如何將文件化成機器能讀懂的數學向量,就是文件前置處理的任務, 主要也有三個步驟:文件斷詞/ 分詞、去雜訊及特徵化。
文件斷詞是將一串連續的文字序列切割成若干個詞,透過一個個完整的詞重新描述語句原來的含意,有利於統計以及後續之運算操作。若是中文或日文等語言,並不像英文在詞與詞之間以一個空白字元做為區隔,因此選擇中文斷詞表現不錯的Jeiba作為前置處理的開源程式庫,而在辭庫學習階段同時使用OpenNLP 進行詞性標注,即每個詞都指派名詞、動詞、形容詞或其他合適的詞性,以及選擇 Atr4s 處理關鍵字抽取的演算法工具。
文件進行斷詞程序之後,還須經過「去除雜訊」。在一篇文章中,有許多語言常用詞,或是冠詞、介詞、副詞與連接詞等這類停止詞 (Stop Words)。停止詞廣泛地出現在各類文件,對於分類的鑑別程度較低,也可能會造成干擾,因此在前置處理階段將停止詞過濾。過濾的方式則是利用統計與詞性辨識的方式建立停止詞表,出現在停止詞表的單詞不納入後續特徵化與建立模型處理。在辭庫學習的技術中,也是經過去除雜訊,產生出符合專利文件分類的技術詞彙。接下來,一般稱為「Bag of words」的模式,是將文件表達為一個特徵向量,每個文件的向量長度是一樣的,向量維度代表出現在專利文件的每一個詞,數字大小即這個詞在文件中出現的次數。如此一來,就把文件轉換成機器學習算演算法可使用的數值向量。
另外一方面,若要提高分類準確度,需要進行特徵值處理。假設語言中的詞彙數是固定且有限的,將其蒐集成詞典,以詞頻統計,再搭配詞頻與反向文件頻率加權 (TF-IDF) 或利用類神經網路技術的 Word2Vec 結合為文件建立特徵向量,來加強文件內部關鍵詞的影響力。因為專利文件的可觀的詞量,考量到效能及資源需求,經過專案團隊測試在分類準確度影響上在可接受的範圍內,採用Word2Vec 將特徵化的向量維度降低來加快訓練的速度。
文件前置處理及特徵值處理之後,則是進行分類模型訓練,在訓練模型時,必須使用具有正確分類標記的文件集進行分類器學習。主要運算的目標是從特徵向量學習到分類規則與特徵權重值;當訓練階段完成時,便將特徵權重紀錄成分類模型。叡揚專案團隊在進行分類訓練前,分別測試 Logistic Regression、SVM 及 XGBoost 三種演算法。其中 XGBoost 可藉由訓練回合數及參數調整,達到平均80%分類預測的準確度,因此採用 XGBoost 作為專利分類模型訓練的機器學習演算法。分類模型建立後,當預測分類錯誤時,我們希望能夠藉由蒐集錯誤分類的回報,來達到調整模型的目的。目前在產業專利知識平台的做法是使用批次的方式,當蒐集到一定程度的錯誤資訊,或者一段固定的時間,將訓練資料與回饋資料合併重新訓練分類模型。
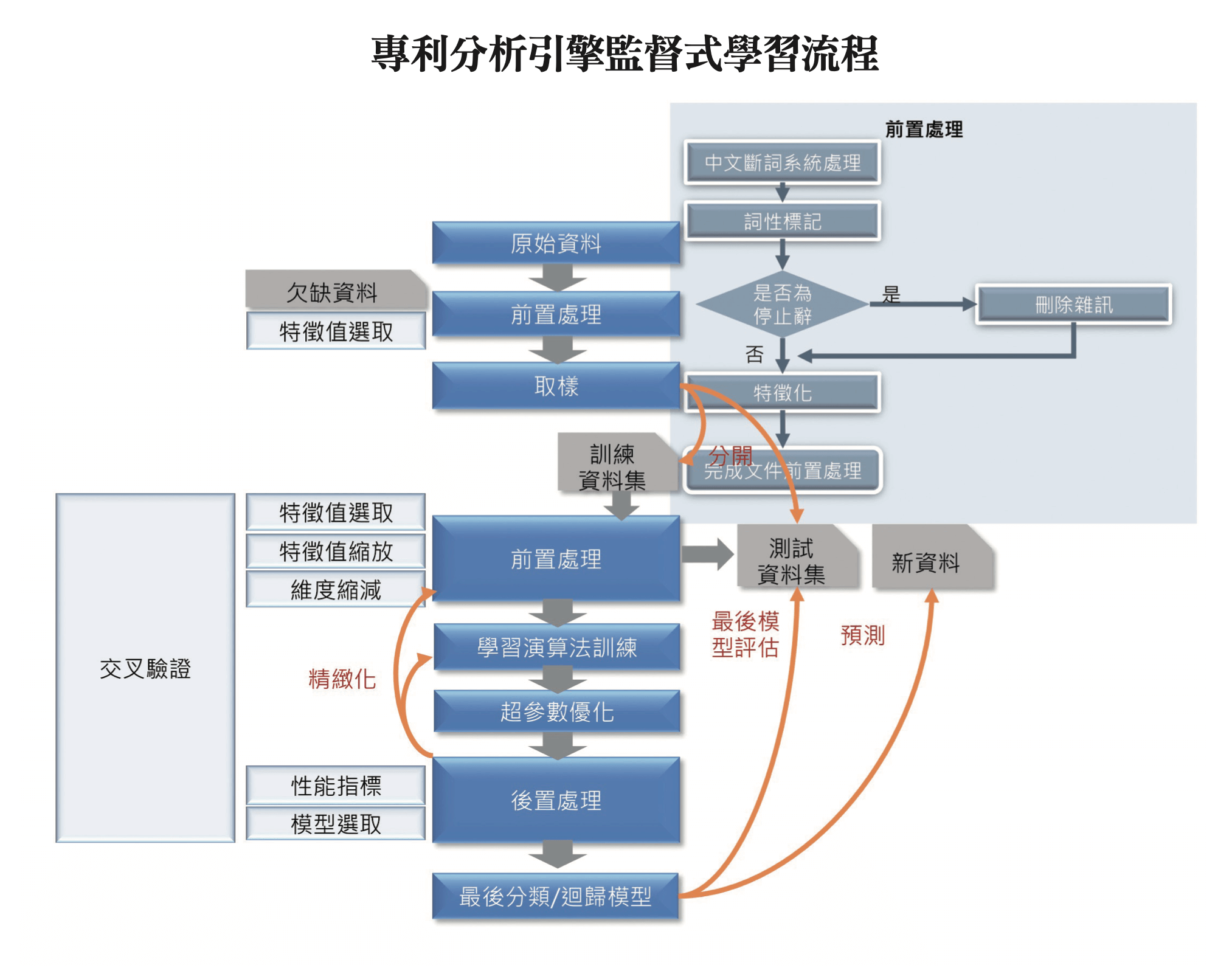
將廠商的 RD 作為智慧局自己的 RD
從需求訪談、平台架構設計、演算技術測試及應用服務開發中,智慧局皆與專案團隊密切合作,尤其是AI 領域技術的導入過程,專案團隊須先實作基本流程,找出適合用於產業專利知識平台的工具及演算法,智慧局一同參與。由於核心技術研發由叡揚資訊的研發單位CII(Central Innovation Institute)創新研究所負責,主管倪文君也非常樂見這樣的發展「以前的研發成果都不知何時可商用化,現在透過與客戶策略結盟,研發成果便有立即成效,對研發人員是一個極大的鼓舞。我們過去研發方向與成果都是給產品或專案使用,但現在也增加直接支援我們重要客戶核心業務的策略,當此策略持續進行,假以時日,我們其他自行研發的成果,客戶自然也會加值運用,形成研發的良性循環,達成客、我、研發團隊多贏結果」。因應物聯網、雲端運算、巨量資料等智慧科技,電子化政府以更為宏觀的角度,運用資料力量、深度的資訊整合與結合群眾智慧,啟動數位政府、創新經濟,達到透明治理與便捷生活。
智慧局積極推動 AI 研發,其實各國專利局也有相關計畫。日本特許廳(日本國家專利局)在 2017 年對外發布日本特許廳人工智慧技術應用之實施及未來行動計畫:從 2016 年中開始,分階段考察各項工作及業務,確認引入 AI 的可能性以進行初步示範驗證。
依據行動計畫,將在 2018 年對電話自動應答、紙質文件電子化和商標分類調查引入 AI 技術試行;而在專利的自動分類及專利檢索等業務工作上,於2019 年將針對研究結果評估後,探討是否導入 AI 技術。相較於此,智慧局在專利 AI 技術應用推展上已毫不遜色。
不同於智慧局全球專利檢索系統幾乎囊括全球所有資料,替產業建立全球圖書館,智慧局對於產業專利知識平台的定位,則是追求深度,希望達到一站式作業,就可滿足需求。
智慧局資訊室一科科長林簡任技正對於產業專利知識平台的形容是「就像替產業建立親切的隔壁書店,求新、求方便,希望達到每天看一次,就可快速獲得最新且全面的專利趨勢。」
智慧局持續透過產業專利知識平台推廣,與產業界合作,共同找尋與逐步構建適合本國的專利平台。叡揚資訊協助打造技術核心,持續運用語意搜尋、文字探勘、知識管理、產業服務及個人化推薦等技術主軸,提供產業內廠商在專利檢索、專利分析及專利管理上更便捷精準的服務。
