若有任何問題請來信:gss_crm@gss.com.tw
RAG 快速上手:Kernel Memory Decoder 開箱即用,輕鬆處理 Office/PDF/HTML

在建構 RAG(Retrieval-Augmented Generation)系統時,處理文件格式與提取文字內容常常是最花時間的步驟。幸好,Microsoft Kernel Memory 提供了一套開箱即用的解碼器(Decoder),可以自動擷取 Office、PDF、HTML 等檔案或網頁中的文字,並直接接入 Chunking 與 Embedding 流程,大幅簡化實作成本。這篇文章將示範如何使用 ExtractFile 方法實現這個過程,讓你專注在打造自己的知識庫與問答服務。
實作
在 Microsoft Kernel Memory 中,針對各種檔案提供對應的 Decoder (HtmlDecoder, MarkDownDecoder, PdfDecoder, MsWordDecoder, MsExcelDecoder, MsPowerPointDecoder ... )來取得它們的文字。如果我們的系統有需要讀取檔案的內容,可以直接利用這些 Decoder 來取得檔案的內容。
以下直接利用 ExtractFile Method 來展示如何使用(請先加入 Microsoft.KernelMemory Nuget 套件),
#pragma warning disable KMEXP00
private static ILoggerFactory loggerFactory;
static async Task<string> ExtractFile(string docPath, bool isUrl = false)
{ var mimeTypeDetection = new MimeTypesDetection();string mimeType;BinaryData? fileBinary;if (isUrl){var webscraper = new WebScraper();var urlDownloadResult = await webscraper.GetContentAsync(docPath);if (!urlDownloadResult.Success){Console.WriteLine(urlDownloadResult.Error);return "";}mimeType = urlDownloadResult.ContentType;fileBinary = urlDownloadResult.Content;}else{mimeType = mimeTypeDetection.GetFileType(docPath);byte[] fileBytes = File.ReadAllBytes(docPath);fileBinary = System.BinaryData.FromBytes(fileBytes);}var msExcelDecoderConfig = new MsExcelDecoderConfig();var msPowerPointDecoderConfig = new MsPowerPointDecoderConfig();var decoders = new List<IContentDecoder>{new TextDecoder(loggerFactory),new HtmlDecoder(loggerFactory),new MarkDownDecoder(loggerFactory),new PdfDecoder(loggerFactory),new MsWordDecoder(loggerFactory),new MsExcelDecoder(msExcelDecoderConfig, loggerFactory),new MsPowerPointDecoder(msPowerPointDecoderConfig, loggerFactory),//new ImageDecoder(ocrEngine, loggerFactory),};var decoder = decoders.LastOrDefault(d => d.SupportsMimeType(mimeType));if(decoder is null){Console.WriteLine($"無法讀取{mimeType}類型的檔案");return "";}var content = await decoder.DecodeAsync(fileBinary);Console.WriteLine("File 文字如下 .....");var textBuilder = new StringBuilder();foreach (var section in content.Sections){var sectionContent = section.Content.Trim();if (string.IsNullOrEmpty(sectionContent)) { continue; }textBuilder.Append(sectionContent);// Add a clean page separationif (section.SentencesAreComplete){textBuilder.AppendLineNix();textBuilder.AppendLineNix();}}var fileText = textBuilder.ToString().Trim();return fileText;
var mimeTypeDetection = new MimeTypesDetection();string mimeType;BinaryData? fileBinary;if (isUrl){var webscraper = new WebScraper();var urlDownloadResult = await webscraper.GetContentAsync(docPath);if (!urlDownloadResult.Success){Console.WriteLine(urlDownloadResult.Error);return "";}mimeType = urlDownloadResult.ContentType;fileBinary = urlDownloadResult.Content;}else{mimeType = mimeTypeDetection.GetFileType(docPath);byte[] fileBytes = File.ReadAllBytes(docPath);fileBinary = System.BinaryData.FromBytes(fileBytes);}var msExcelDecoderConfig = new MsExcelDecoderConfig();var msPowerPointDecoderConfig = new MsPowerPointDecoderConfig();var decoders = new List<IContentDecoder>{new TextDecoder(loggerFactory),new HtmlDecoder(loggerFactory),new MarkDownDecoder(loggerFactory),new PdfDecoder(loggerFactory),new MsWordDecoder(loggerFactory),new MsExcelDecoder(msExcelDecoderConfig, loggerFactory),new MsPowerPointDecoder(msPowerPointDecoderConfig, loggerFactory),//new ImageDecoder(ocrEngine, loggerFactory),};var decoder = decoders.LastOrDefault(d => d.SupportsMimeType(mimeType));if(decoder is null){Console.WriteLine($"無法讀取{mimeType}類型的檔案");return "";}var content = await decoder.DecodeAsync(fileBinary);Console.WriteLine("File 文字如下 .....");var textBuilder = new StringBuilder();foreach (var section in content.Sections){var sectionContent = section.Content.Trim();if (string.IsNullOrEmpty(sectionContent)) { continue; }textBuilder.Append(sectionContent);// Add a clean page separationif (section.SentencesAreComplete){textBuilder.AppendLineNix();textBuilder.AppendLineNix();}}var fileText = textBuilder.ToString().Trim();return fileText;
}
在ExtractFile Method中,我們將 Microsoft Kernel Memory 中提供的 Decoder 組合起來,要取得檔案內容時,再依檔案的 mimeType 來取得對應的 Decoder 進行讀取檔案內容。
以下分別針對 Word、PDF、HTML 及 2 欄式PDF 來試看看效果。
var docPath = @"new1.docx";
var docBody = await ExtractFile(docPath);
Console.WriteLine($"{docPath} ========");
Console.Write(docBody);
var pdfPath = @"pdf1.pdf";
var pdfBody = await ExtractFile(pdfPath);
Console.WriteLine($"{pdfPath} ========");
Console.Write(pdfBody);
var urlPath = "https://www.taisugar.com.tw/resting/hualian/CP2.aspx?n=12036";
var urlBody = await ExtractFile(urlPath, true);
Console.WriteLine($"{urlBody} ========");
Console.Write(urlBody);
Word + Table 的效果如下,
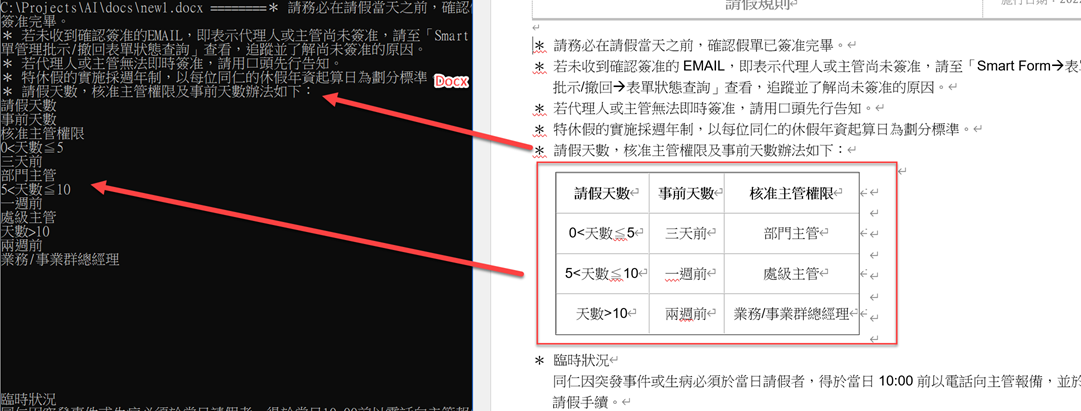
註: 它會連 追蹤修訂 都一併取出來
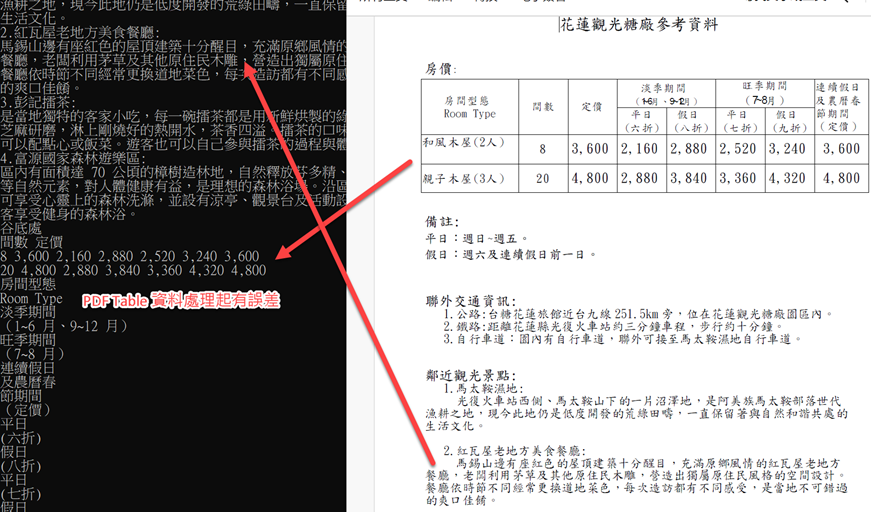
PDF 的效果如下,可以發現”請假天數,核准主管權限及事前天數辨法如下:” 的 Table 跑到了比較下面的地方
HTML 的效果如下,
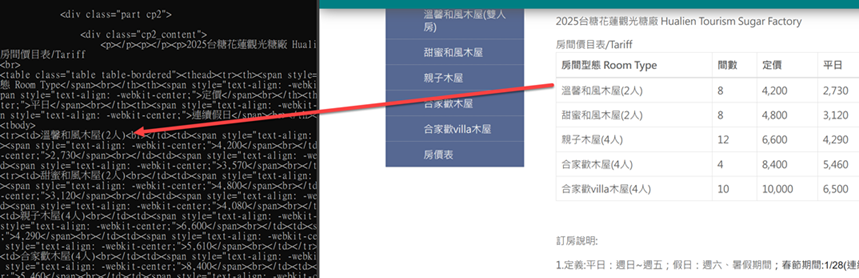
2 欄式PDF的效果如下,和上面 PDF + Table 狀況一樣,Table 跑到了整頁的最後去了~~

- 當 PDF 中有 Table 時,Table文字的內容會跑到後面去,如果有上/下文關係,有可能就會判斷錯誤。
結論
透過 Kernel Memory 的各種 Decoder,我們可以「開箱即用」地擷取 Office、PDF、HTML 等各種檔案與網頁的內容,省去手動解析的繁瑣過程,並且無縫銜接 TextChunker 與向量化流程,讓建構 RAG 系統變得更加輕量與模組化。這不僅提升了開發效率,也降低了知識庫擴充的門檻 ,同時也提供了擴充的彈性。
如果你正考慮導入 LLM 或建立企業內部搜尋引擎、FAQ 系統、智能客服,這種可組合、可擴充的做法會是非常實用的起點。
參考資源
Extract Text From a Multi-Column Document Using PyMuPDF in Python
使用 Kernel Memory 和 MSSQL 快速建立 RAG 服務
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
評論