若有任何問題請來信:gss_crm@gss.com.tw
Vibe Coding LLM 輔助Coding 由AI生成商用系統的實際可行性

Vibe,跟著感覺走的意思。但如果還是不知道Vibe Coding是什麼意思的話,可以去聽聽蘇芮「跟著感覺走」這首歌,然後想像著歌詞是形容在 Coding 的過程,或許你就能了解什麼是 Vibe Coding 了。
其實 Vibe Coding 的定義蠻嚴格的,包括要求由100% 使用由AI工具生成的程式碼,不可以由人再去修改生成出來的程式,若要調整或修改,必須完全依靠AI工具透過 Prompt 的方式來調整,若執行有錯誤,則要把 Error Message 貼回AI工具,讓AI來 Debug 及修正。依過去的傳統(其實也不過半年前),利用 LLM 的 Chat 介面或 Github Copilot 等方式來協助開發,都還不能算是完整的 Vibe Coding,只能算是 LLM 輔助 Coding。
但目前在商用系統的開發,若打算依靠AI生成似乎還有很多疑慮,「商用」也代表我們對客戶在品質及安全上的承諾,這中間很多我們需要擔心的事,例如資料處理的正確性、資料庫效能、程式及資料的安全性、套件使用授權的合法性、還要考慮未來可能長達10年的可維護性及擴充性等。因此,Vibe Coding 或 LLM 輔助 Coding,目前大概是還在「你敢做我還不敢用」的狀態。
但透過AI生成程式碼,在商用系統開發人員其實有一個還不錯的用處,就是用來開發團隊內部自用的「小工具」,例如資料整理工具、測試資料產生器、SQL語法產生器等,利用這些小工具協助自己及團隊更快速的完成商用系統開發或測試等工作,的確是個不錯的選擇,另一方面也透過這個過程,增加自己在AI功能的開發經驗,讓自己加深了解LLM等AI運作的原理。
你只要想像一個情景:團隊今天突然來了一個又急又煩的工作需要完成,心裡正想著「若是有個小工具幫忙跑一下就好了」,如果是以前你會判斷若現在才來寫工具已經來不及了,但今天,不管你是要用真正的Vibe Coding,還是 LLM 輔助 Coding,就正是時候了。
以下,我們分享一個利用 LLM 輔助生成小工具的實際過程紀實,但並不是 Vibe Coding,也沒有用 Cursor、Windsurf 或 VS Code + Github Copilot 等整合型AI開發工具,也完全不用最強的 ChatGPT,只用安裝在 NB 上 12B 開源的 LLM 來完成。
環境說明:
電腦:ASUS ROG Strix SCAR 18:RTX 4090 16GB
主要工具:Open WebUI + VS Code
使用模型:Google Gemma 3 12B
開發語言:Python (偶是Python小白)
故事的起源…是這樣的:
有一個星期天下午,在家裡想到,現在不管你原本是 .NET 還是 JAVA 人員,要開發AI相關的功能,不會 Python 大概是活不下去了,若要普訓,是否有合適的講師?而找到講師是一件事,準備教材又是另一件事,教材大概也是需要花不少準備時間,若有工具能產生教材,就可以大大節省講師的準備時間了。
只要「若有工具能XXX就好了」的 Pattern 在心裡OS出現時,就正正是用AI輔助做出工具的好時機呀!!
第一步:大約花了5分鐘
倒杯熱的黑咖啡,打開花了10萬但從未拿來玩過3A遊戲大作的電競NB ~><~,插上耳機打開Spotify,點開自己建立的播放清單「DJoe-傷心情歌」
https://open.spotify.com/playlist/57ujTyYQPtog3zAgUPjOP0?si=6f11f4eebdfb482a
第二步:大約花了10分鐘
打開又快又好用的 NotePad(沒有++),現在記事本還支援自動存檔,開始做功能規劃的構想,既然要做,最後決定用途可以用廣一點,不要只能做 Python 的訓練教材,初步構想的內容完整如下,基本上就是自己看得懂就好(用手寫可能更好,確保只有自己看得懂):

第三步:大約花了5分鐘
把第二步的粗略構想,改寫成 Prompt。當然,我覺得直接貼構想的文字,大概也可以開始,但既然程式都不打算寫了,Prompt Engineering 還是花一點時間寫好一點,這樣才對得起資訊工程之神吧
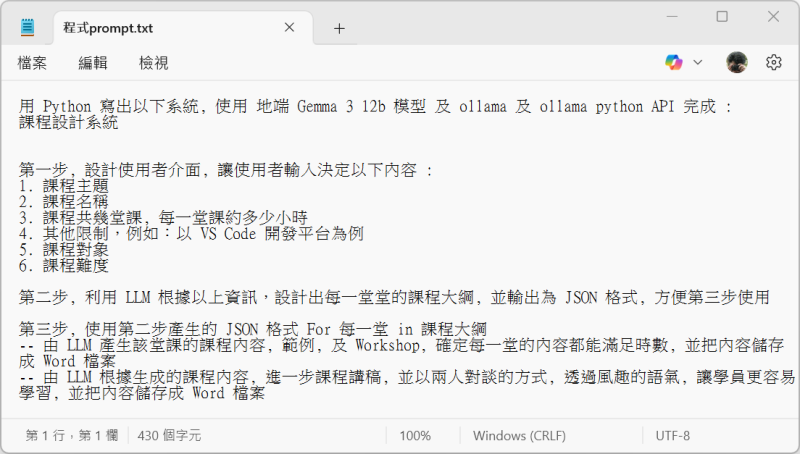
第四步:大約花了3分鐘 (接龍式的UI生成真的是好設計,不知不覺就浪費你3分鐘)
打開最近有拿來玩 Balatro 的電競NB上,之前就安裝好的 Open WebUI,選擇預先透過 Ollama 拉下來的 Google Gemma 3 12B模型,把 Prompt 貼上後,Gemma 3 的完整回應如下:
好的,這是一個使用 Ollama 和本地 Gemma 3 12b 模型來實現課程設計系統的 Python 程式碼框架。由於完整的實現需要處理 UI、檔案 I/O、Word 檔案生成等細節,這裡提供一個核心邏輯的示例,並提供一些提示和建議。
請注意:
- 環境準備: 確保已安裝 Ollama,並已下載 Gemma 3 12b 模型。
- API 金鑰: 此範例假設您使用本地 Ollama 伺服器,因此不需要 API 金鑰。
- Word 檔案生成: 此範例僅提供生成 Word 檔案的提示,實際的 Word 檔案生成需要使用
python-docx或其他類似的函式庫。 - 錯誤處理: 程式碼中缺少完整的錯誤處理機制,請根據實際情況添加。
import ollama
import json
import os
from docx import Document # 需安裝 python-docx
def get_user_input():
"""獲取使用者輸入"""
course_theme = input("請輸入課程主題: ")
course_name = input("請輸入課程名稱: ")
num_lessons = int(input("請輸入課程共幾堂課: "))
lesson_duration = int(input("每一堂課約多少小時: "))
constraints = input("請輸入其他限制 (例如: 以 VS Code 開發平台為例): ")
target_audience = input("請輸入課程對象: ")
difficulty = input("請輸入課程難度: ")
return {
"course_theme": course_theme,
"course_name": course_name,
"num_lessons": num_lessons,
"lesson_duration": lesson_duration,
"constraints": constraints,
"target_audience": target_audience,
"difficulty": difficulty
}
def generate_course_outline(user_input):
"""使用 LLM 根據使用者輸入生成課程大綱"""
prompt = f"""
請根據以下資訊設計課程大綱:
課程主題:{user_input['course_theme']}
課程名稱:{user_input['course_name']}
課程對象:{user_input['target_audience']}
課程難度:{user_input['difficulty']}
課程共 {user_input['num_lessons']} 堂課,每一堂課約 {user_input['lesson_duration']} 小時。
限制:{user_input['constraints']}
請以 JSON 格式輸出課程大綱,包含每堂課的標題和簡要描述。
"""
response = ollama.generate(model='gemma-3', prompt=prompt, max_tokens=500)
try:
course_outline = json.loads(response.response)
return course_outline
except json.JSONDecodeError:
print("LLM 回應格式錯誤,請檢查提示詞或模型設定。")
return None
def generate_lesson_content(course_outline):
"""為每一堂課生成課程內容、範例和 Workshop"""
lesson_contents = []
for i, lesson in enumerate(course_outline):
lesson_number = i + 1
lesson_title = lesson['title']
prompt = f"""
請為課程 {lesson_number},主題為 {lesson_title},生成詳細的課程內容、範例和 Workshop。
請確保內容能夠滿足 {course_outline[0]['lesson_duration']} 小時的時長。
請以 Markdown 格式輸出。
"""
response = ollama.generate(model='gemma-3', prompt=prompt, max_tokens=1000)
lesson_content = response.response
# 儲存為 Word 檔案 (需要 python-docx)
document = Document()
document.add_heading(f"課程 {lesson_number}: {lesson_title}", level=1)
document.add_paragraph(lesson_content)
document.save(f"lesson_{lesson_number}_{lesson_title}.docx")
lesson_contents.append({
"lesson_number": lesson_number,
"lesson_title": lesson_title,
"content": lesson_content
})
return lesson_contents
def generate_lecture_script(lesson_content):
"""根據課程內容生成課程講稿 (兩人對談方式)"""
prompt = f"""
請根據以下課程內容,生成課程講稿,以兩人對談的方式呈現,並使用風趣的語氣:
{lesson_content}
請以 Markdown 格式輸出。
"""
response = ollama.generate(model='gemma-3', prompt=prompt, max_tokens=1000)
lecture_script = response.response
# 儲存為 Word 檔案 (需要 python-docx)
document = Document()
document.add_heading(f"課程講稿: {lesson_content}", level=1)
document.add_paragraph(lecture_script)
document.save("lecture_script.docx")
return lecture_script
def main():
"""主程式"""
user_input = get_user_input()
course_outline = generate_course_outline(user_input)
if course_outline:
print("課程大綱:", json.dumps(course_outline, indent=4))
lesson_contents = generate_lesson_content(course_outline)
for lesson in lesson_contents:
lecture_script = generate_lecture_script(lesson['content'])
print(f"已生成課程 {lesson['lesson_number']} 的講稿。")
if __name__ == "__main__":
main()程式碼說明:
get_user_input(): 獲取使用者輸入的課程資訊。generate_course_outline(): 使用 LLM 根據使用者輸入生成課程大綱,並以 JSON 格式輸出。generate_lesson_content(): 針對每一堂課,使用 LLM 生成詳細的課程內容、範例和 Workshop,並儲存為 Word 檔案。generate_lecture_script(): 根據課程內容,使用 LLM 生成課程講稿,以兩人對談的方式呈現,並儲存為 Word 檔案。main(): 主程式,調用各個函式,完成課程設計流程。
使用方法:
- 安裝 Ollama 和 Gemma 3 12b 模型。
- 安裝
python-docx函式庫:pip install python-docx - 執行 Python 程式碼。
- 根據提示輸入課程資訊。
- 程式碼將生成課程大綱、課程內容 (Word 檔案) 和課程講稿 (Word 檔案)。
注意事項:
- 提示詞工程: LLM 的輸出品質很大程度上取決於提示詞的設計。請根據實際需求調整提示詞,以獲得更好的結果。
- 時長控制: LLM 預估時長可能不準確。請根據實際情況調整內容,以確保時長符合要求。
- 錯誤處理: 程式碼中缺少完整的錯誤處理機制,請根據實際情況添加。
- Word 檔案生成: 此範例僅提供生成 Word 檔案的提示,實際的 Word 檔案生成需要使用
python-docx或其他類似的函式庫。 - 模型選擇: 可以根據需求選擇不同的 LLM 模型。
這個框架提供了一個起點,您可以根據自己的需求進行擴展和修改。希望這個程式碼對您有所幫助!
第五步:大約花了5分鐘
進入實際開發(?),打開 VS Code後,先開始執行標準步驟:建立目錄,建立空的m ain.py,建立 venv 環境。然後不管 LLM 產生其他廢話,把Gemma 3產生的 Python 區塊貼上去。把額外需要安裝的套件安裝好,以生成出來的 Code 來說,就是要裝 python-docx 及 Ollama python API,但後者可能因為我們在 Prompt 裡已經指定要用 Ollama python API 來完成,所以生成的說明中,就沒有特別提醒我們要安裝,所以最後 pip install python-docx 及 pip install ollama 把套件裝起來。
第六步:大約花了3分鐘
先手動修改一個不小心一眼就瞄到的小問題:在 Ollama 裡 Gemma 3的名稱是 "gemma3:12b";另外也覺得沒必要限制 token 數,所以拿掉max_token,最後手動把呼叫LLM的都從
response = ollama.generate(model='gemma-3', prompt=prompt, max_tokens=1000)
改為
response = ollama.generate(model='gemma3:12b', prompt=prompt)
第七步:大約花了5分鐘
其他看不懂的 Python 不想管啦,直接執行下去!果然,不出意外就出意外了,發生錯誤。不過其實有跑了幾分鐘,而且電腦散熱風扇有起飛的聲音才結束的,並出現「LLM 回應格式錯誤,請檢查提示詞或模型設定。」的訊息,所以心裡有譜,起碼有成功跑完第一段 Prompt 後才掛掉的。
第八步:大約玩了10分鐘
雖然是AI的錯,但只要是Bug第一時間就是不想面對,所以打開Balatro玩了兩局(反正有訂閱 XBOX Game Pass Ultimate,不玩白不玩),結果一直沒抽到高倍數的Joker,心情就更差了…
第八步:大約花了20分鐘
看了一下,不是什麼大錯誤,只是因為 Prompt 裡雖然已經有指定回應 JSON 格式,但實際生成的內容裡還是有多了不是純 JSON 的文字內容。
明知道單純用 Prompt 本來就無法確保每次都回應純 JSON 格式,所以懶得再去試 Prompt,直接改寫用 Ollama 的 Structured Output 功能,並且配合Prompt 的調整指定輸出 JSON 格式。(Ollama 的 Structured Output 這裡就不細說了,請自己參考:https://ollama.com/blog/structured-outputs)
該段改成這樣:
def generate_course_outline(user_input):
"""使用 LLM 根據使用者輸入生成課程大綱"""
prompt = f"""
請根據以下資訊設計課程大綱:
課程主題:{user_input['course_theme']}
課程名稱:{user_input['course_name']}
課程對象:{user_input['target_audience']}
課程難度:{user_input['difficulty']}
課程共 {user_input['num_lessons']} 堂課,每一堂課約 {user_input['lesson_duration']} 小時。
限制:{user_input['constraints']}
請以以下 JSON 格式輸出課程大綱,包含每堂課的標題和簡要描述,不需要額外的說明及解釋:
{{
"lessons": [
{{
"lesson_number": 1,
"title": "?",
"duration": "?",
"description": "?"
}},
{{
"lesson_number": 2,
"title": "?",
"duration": "?",
"description": "?"
}},
{{
"lesson_number": 3,
"title": "?",
"duration": "?",
"description": "?"
}}
]
}}
"""
format = {
"type": "object",
"properties": {
"lessons": {
"type": "array",
"lesson_number": {
"type": "string"
},
"title": {
"type": "string"
},
"duration": {
"type": "string"
},
"description": {
"type": "string"
}
}
},
"required": [
"lessons",
"lesson_number",
"title",
"duration",
"description"
]
}
response = ollama.generate(model='gemma3:12b', prompt=prompt, format=format)
try:
course_outline = json.loads(response.response)
return course_outline
except json.JSONDecodeError:
print("LLM 回應格式錯誤,請檢查提示詞或模型設定:" + response.response)
return None第九步:大約執行了10分鐘
第三輪的執行… 成功了!(灑花)
加總起來大約總共花大約一小時,其中改寫用 Structured Output 及處理 JSON 佔了最多時間。
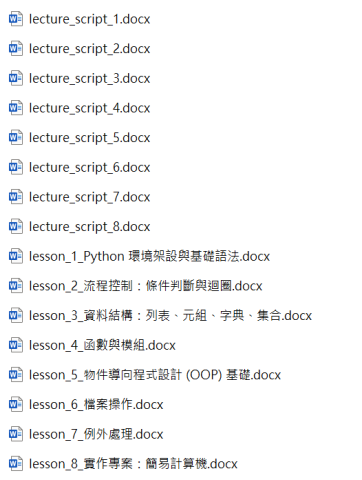
在目錄就可以得到以下的結果,包括8堂課程內容及兩個角色的對話檔 (lecture_script.docx):

不過,看一下內容立即會發現三個問題:
- Markdown 格式內容直接以純文字的方式產生在 Word 裡很難讀,可讀性非常低。(如下圖)
- lecture_script.docx 只剩下第8課的對談內容,因為每一個對談都會蓋掉上一課的對談檔。
- 檔案直接生在程式目錄,看到實在很礙眼…

第十步:大約花10分鐘
解問題先解 Bug 是不變的道理,所以把原本手動改過的程式貼回 Open WebUI,並同時下以下 Prompt:「(貼上修改過的程式碼) 我已經手動修改程式如上,但產生 lecture_script.docx 時每一堂課的對談都會蓋掉上一堂課的內容,改為每一堂課都有自己的對談版本檔案。」
但發現結果不太好,重新生成了三次都有一樣的問題:
- 會開始出現簡中
- 生成的程式碼很不完整,原本我寫好的直接被刪掉
- 會忘了我們原本的目標
突然想起自己沒有改 Open WebUI 裡 Gemma 3 的 Context length,預設還停在 2048 (2K),所以把參數改為130,000 (理論可到 128K)。
第十一步:大約花20分鐘 (含執行10分鐘)
Context length 放大後,明顯感受到生成的速度變慢,體感上從約每秒 20~30 tokens 掉到只有約每秒 5~10 tokens。但生成的結果已經完全沒有上述的問題。
但產生的程式也還是錯的,它是增加了把空白取代為"_" 就以為可以解決檔案重覆的問題:
document.save(f"lecture_script_{lesson_content.replace(' ', '_')}.docx")
所以,再把上述的 Prompt 改為:「(貼上修改過的程式碼)我已經手動修改程式如上,但產生 lecture_script.docx 時每一堂課的對談都會蓋掉上一堂課的內容,改為 lecture_script.docx 檔案名稱增加課程編號,避免檔案重覆的問題。」其實這個問題若直接手工改,應該5分鐘就可以解決,但前前後後包括重覆嘗試及 Prompt 的調整,總共花了約20分鐘。總於生成出「大致上」正確的修正版程式了,其中它主要修正這片段:
def generate_lecture_script(lesson_content):
"""根據課程內容生成課程講稿 (兩人對談方式)"""
prompt = f"""
請根據以下課程內容,生成課程講稿,以兩人對談的方式呈現,並使用風趣的語氣:
{lesson_content}
請以 Markdown 格式輸出。
"""
response = ollama.generate(model='gemma3:12b', prompt=prompt)
lecture_script = response.response
# 儲存為 Word 檔案 (需要 python-docx)
document = Document()
document.add_heading(f"課程講稿: {lesson_content}", level=1)
document.add_paragraph(lecture_script)
document.save(f"lecture_script_{lesson_number}.docx") # 修改檔案命名
return lecture_script
不過,還沒執行就看到一個問題,generate_lecture_script 根本沒傳入 lesson_number,document.save(f"lecture_script_{lesson_number}.docx") 一定會死,所以不忍了,直接下手改一下:
def generate_lecture_script(lesson_content, lesson_number):
"""根據課程內容生成課程講稿 (兩人對談方式)"""
prompt = f"""
請根據以下課程內容,生成課程講稿,以兩人對談的方式呈現,並使用風趣的語氣:
{lesson_content}
請以 Markdown 格式輸出。
"""
response = ollama.generate(model='gemma3:12b', prompt=prompt)
lecture_script = response.response
# 儲存為 Word 檔案 (需要 python-docx)
document = Document()
document.add_heading(f"課程講稿: {lesson_content}", level=1)
document.add_paragraph(lecture_script)
document.save(f"lecture_script_{lesson_number}.docx")
return lecture_script
突然佩服起堅持不動手改的純種 Vide Coding 人了。 接下來跑測試,大約跑10分鐘,就順利產生了10個課程及10個對談版本。
第十二步:大約花30分鐘
接下來要來解決 Markdown 格式被直接塞進Word裡可讀性的問題,想起 Aspose.Word 就有 Markdown 2 Word 的功能,但礙於那是收費套件,所以就來試試叫 Gemma 3 解決看看,利用接續對話:「但此程式產生出來的 Word 裡的 Markdown 格式可讀性很低,增加將 Markdown 各種格式都完整轉換成 Word 樣式的功能,並特別針對程式碼片段,以程式碼方式特別排版方式處理。」
但結果出來又開始亂了,所以這次放棄多輪對話,另起新對話把程式碼及上面的 Prompt 再重貼一次。(這時候又感受到整合型工具的好處了,若自己也能寫一個 VS Code 的 Extension 就好了。)
又同時想起之前一直沒寫 System Prompt,雖然程式碼也沒什麼問題,但廢話就很多,也佔 Token 數,所以在 Open WebUI 上把 Gemma 3 的 System Prompt 先簡單寫一寫:
你是一個 python 程式高手,可以協助使用者依據需求生成 python 程式碼。並遵守以下規則:
- 只生成完整的 python 程式碼,不需要額外的說明或解釋
通過作者
- 程式註解及文字內容一律使用繁體中文
在 Open WebUI 上開啟新對話,再輸入以下內容:
這是我已經寫好的程式,用於課程設計,並依使用者輸入的需求生成課程內容及輕鬆的對談講稿:
(完整程式碼…略)
但程式執行結果的 Word 裡直接放入 Markdown 格式,可讀性很低,把程式修改為:將 Markdown 轉換成可讀性高的 Word 樣式版本,並需額外處理程式碼片段的排版方式。
不過…
本階段結果:非常不理想,重覆試了幾次,用它修改的程式再重新生成的 Word 裡,格式實際並沒有變好。
第十三步:大約花30分鐘
決定上網搜尋方案,除了找到一些需要費用的套件,可行的方法並不多,但發現比較多人做 Markdown to HTML,所以改變方向,找到Python-Markdown套件及CodeHilite等關鍵字,把第十二步的 Prompt 改成:
這是我已經寫好的程式,用於課程設計,並依使用者輸入的需求生成課程內容及輕鬆的對談講稿:
(完整程式碼…略)
把程式修改為:利用 Python-Markdown 套件,將 Markdown 轉換成可讀性高的 HTML 檔案,並利用 CodeHilite extension 額外處理程式碼片段的排版。
通過作者
最終大致上已經好很多了(如下圖),但程式碼片段排版並沒有完全解決顯然 CodeHilite extension 的用法沒那麼簡單,不過這次就先到這裡了。

最後一步:大約30分鐘 (包括執行了兩次共 20 分鐘)
下最後一道 Prompt:
「改為每次執行都建立一個以執行時間YYYYMMDDHHMM為名稱的新目錄,並把HTML檔案改為產生於目錄中。」
最後它生成的程式裡的一些小錯誤,至此已經不想再說了,反正都手工修正就好了,失去耐心了...
如果是開發人員犯這種錯,已經開罵,偏偏它又只是用LLM,罵它也是浪費力氣。最後,也順手補了一些比較正常的訊息處理。
未完成事項:
- 課程文件裡的程式碼格式排版問題。
- 尚未校正生成的「內容」,包括課程內容及對話內容,還需要調整Prompt。
- 目前八堂課的對談人物是誰,並沒有一致性,還需要調整 Prompt。
- 未來看是要擴充 GUI,還是包成API…又或者…Why not both?
感想:
- 一開始忘了先寫個 System Prompt 是傻了
- 第一次從無到有生成程式碼效率提升最高,但隨著後續每次修 Bug 或功能的修改,效率會呈指數型下降,當然,這跟對程式的熟識度也有差別,本來就不會寫程式的人,怎麼樣都是用生成最快
- 未來(指一年內,我無力預估二年後會發生什麼事)70~80%的程式碼由AI生成,而且生成的人不一定是工程師,最後會需要「夠細心」的工程師進行最後的精雕細琢,最終只剩下有這種能力以及有解決問題能力的工程師能存活下來。
- 若修改也要用,會非常需要整合型的工具,才能免除掉一直複製貼上的問題
- 因程式碼的特性,Context Length 的限制的影響比一般的文字生成更巨
- 也因為 Context Length 的限制,每個單獨的程式單檔愈小,或許效果愈好
- 整合 RAG,搜尋內外部程式的寫法,有效提升程式碼的多樣性或功能性
- 細節決定一切,愈在乎細節,後期會愈無力,就跟交待一件事給同事,同事做的很快,但已經做了十次,實際產出都不如理想,漸漸就會失去耐性
- 當然,若是用 Cursor 或 Windsurf 等工具,可以有 IDE 整合、執行測試、跨檔案處理等,我相信上述的問題一定會有所改善。但我始終喜歡知道基礎學習,再一步一步推疊新技術、新工具,而非不明就理只會用工具,這時候我們就真的只會變成「工具人」。
後記1:這篇文章堅持不用AI寫,也不用AI校稿,程式已經給AI寫,文章也給AI寫的話,我還是個人嗎?保留原汁原味的個人風格,有錯別字就隨它去吧,留點工作給北投金城武來做。
後記2:其實寫這篇文章的時間,比寫出小工具的時間更長。
後記3: 一個不會寫 python 的人,寫了一支 python 的程式用來生成 python 的訓練內容,怎麼想都覺得有點微妙 (; ・`д・´)
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
評論 6
請問您的筆電在魔物獵人:荒野效能測試跑分如何?
就說還沒有拿來玩過3A遊戲大作囉
似乎看不到作者是哪位大神啊?
┑( ̄Д  ̄)┍
( ̄﹁ ̄)
原來4090 有16gb@@
我以為只有24的