若有任何問題請來信:gss_crm@gss.com.tw
用 Kernel Memory 搭配 MSSQL 快速打造 RAG 系統|DB 結構與操作深度解析

前言
在前一篇 使用 Kernel Memory 和 MSSQL 快速建立 RAG 服務 可以很快建立出 RAG 服務,並讓使用者進行問答。
本文介紹如何使用 Kernel Memory 搭配 Microsoft SQL Server,針對 MSSQL Table 進行結構解析與資料處理,並將其應用於 Retrieval-Augmented Generation(RAG)系統中。內容涵蓋資料表結構對應、資料向量化、Embedding 儲存與查詢邏輯等完整流程。
研究
首先,就從上傳文件成為知識庫開始,透過 MemoryWebClient.ImportDocumentAsync 將文件上傳給 Kernel Memory Service(API),程式碼為 await kmClient.ImportDocumentAsync(docPath, index: tenantId, documentId: documentId);
它會呼叫 Kernel Memory 的/upload API,
呼叫MemoryServerless.ImportDocumentAsync(因為OrchestrationType 設定成 InProcess),
呼叫BaseOrchestrator.ImportDocumentAsync執行Pipeline的處理,
因為沒設定 Pipeline 自定的 Steps,所以會使用預設的 Steps,
預設的 Steps 為
1.extract(讀取文件內容),
2.partition(將文件內容切成多個 Chunks),
3.gen_embeddings(將各 Chunks 轉成 Embedding)
4.save_records(將 Chunks 及 Embeddings 存到 MSSQL)
在save_records時,會做以下幾個步驟:
1.建立基本 Tables
建立KMCollections及KMMemories(config 中 SqlServer 區段MemoryCollectionTableName及MemoryTableName的設定值)這 2 個 Table(SqlServerMemory.CreateTablesIfNotExistsAsync)。KMCollections Table 只有一個id nvarchar(256)這個欄位,是記錄index的值。KMMemories Table 會記錄文件 Chunks 的相關內容, payload 欄位包含了 Chunk 的文字、檔案資訊等等內容。,Table 及 Script 如下,
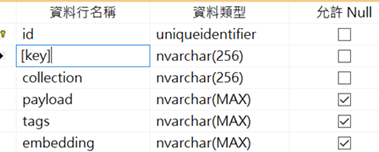
IF OBJECT_ID(N'[dbo].[KMCollections]', N'U') IS NULL CREATE TABLE [dbo].[KMCollections]( [id] NVARCHAR(256) NOT NULL,PRIMARY KEY ([id]));
CREATE TABLE [dbo].[KMCollections]( [id] NVARCHAR(256) NOT NULL,PRIMARY KEY ([id]));
IF OBJECT_ID(N'[dbo].[KMMemories]', N'U') IS NULLCREATE TABLE [dbo].[KMMemories]( [id] UNIQUEIDENTIFIER NOT NULL,[key] NVARCHAR(256) NOT NULL,[collection] NVARCHAR(256) NOT NULL,[payload] NVARCHAR(MAX),[tags] NVARCHAR(MAX),[embedding] NVARCHAR(MAX),PRIMARY KEY ([id]),FOREIGN KEY ([collection]) REFERENCES [dbo].[KMCollections]([id]) ON DELETE CASCADE,CONSTRAINT UK_KMMemories UNIQUE([collection], [key]));
2.新增index資料及建立index所需的 Tables(DefaultQueryProvider.PrepareCreateIndexQuery)
2.1.將index(gss)新增到KMCollectionsTable 中
2.2.建立KMEmbeddings_[index]及KMMemoriesTags_[index](config 中 SqlServer 區段EmbeddingsTableName及TagsTableName的設定值)這 2 個 Table。(如果不存在才建立)
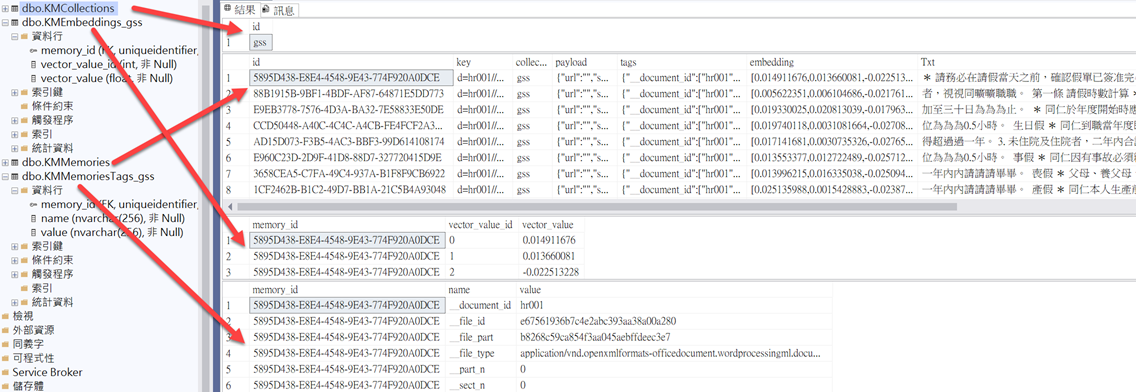
BEGIN TRANSACTION;INSERT INTO [dbo].[KMCollections]([id])VALUES ('gss');IF OBJECT_ID(N''[dbo].[KMMemoriesTags_gss]'', N''U'') IS NULLCREATE TABLE [dbo].[KMMemoriesTags_gss]([memory_id] UNIQUEIDENTIFIER NOT NULL,[name] NVARCHAR(256) NOT NULL,[value] NVARCHAR(256) NOT NULL,FOREIGN KEY ([memory_id]) REFERENCES [dbo].[KMMemories]([id]));IF OBJECT_ID(N''[dbo].[KMEmbeddings_gss]'', N''U'') IS NULLCREATE TABLE [dbo].[KMEmbeddings_gss]([memory_id] UNIQUEIDENTIFIER NOT NULL,[vector_value_id] [int] NOT NULL,[vector_value] [float] NOT NULL,FOREIGN KEY ([memory_id]) REFERENCES [dbo].[KMMemories]([id]));IF OBJECT_ID(N''[dbo.IXC_KMEmbeddings_gss]'', N''U'') IS NULLCREATE CLUSTERED COLUMNSTORE INDEX [IXC_KMEmbeddings_gss]ON [dbo].[KMEmbeddings_gss];
COMMIT;
index 相關的 Table 是將Tags及Embeddings每個項目存成一筆資料。
3.建立好Table後,再來就是刪除舊資料(如果有的話),
讀取 _files/gss/hr001/__pipeline_status.json 將舊的 Embeddings 資料刪除(artifact_type為TextEmbeddingVector的資料),然後 Loop 去執行刪除。
__pipeline_status.json 中的相關的內容如下,
"content.url.partition.0.txt.AI.OpenAI.OpenAITextEmbeddingGenerator.__.text_embedding":
{"id": "6dd4ed22dbc44e68988f2f047298e327","name": "content.url.partition.0.txt.AI.OpenAI.OpenAITextEmbeddingGenerator.__.text_embedding","size": 12894,"mime_type": "float[]","artifact_type": "TextEmbeddingVector","partition_number": 0,"section_number": 0,"tags": {},"parent_id": "9b4717098c9c4f858247255f408e44d0","source_partition_id": "d6388425c3cc45e9986397a60e09b1d4","content_sha256": "","processed_by": ["gen_embeddings","save_records"]
}
刪除的Script 如下,
BEGIN TRANSACTION;DELETE [tags]FROM [dbo].[KMMemoriesTags_gss] [tags]INNER JOIN [dbo].[KMMemories] ON [tags].[memory_id] = [dbo].[KMMemories].[id]WHERE[dbo].[KMMemories].[collection] = N'gss'AND [dbo].[KMMemories].[key]=N'd=hr001//p=每段的Id';DELETE [embeddings]FROM [dbo].[KMEmbeddings_gss] [embeddings]INNER JOIN [dbo].[KMMemories] ON [embeddings].[memory_id] = [dbo].[KMMemories].[id]WHERE[dbo].[KMMemories].[collection] = N'gss'AND [dbo].[KMMemories].[key]=N'd=hr001//p=每段的Id';DELETE FROM [dbo].[KMMemories]WHERE [collection] = N'gss' AND [key]=N'd=hr001//p=每段的Id';
COMMIT;
4.將 Chunks 資料新增/修改到 KMMemories, KMEmbeddings_gss 及 KMMemoriesTags_gss 資料表(gss 為index名),Loop 執行
BEGIN TRANSACTION;-- 每段 Chunks 資料MERGE INTO [dbo].[KMMemories]USING (SELECT N'd=hr001//p=每段的Id') as [src]([key])ON [dbo].[KMMemories].[key] = [src].[key]WHEN MATCHED THENUPDATE SET payload=N'{"url":"","schema":"20231218A","file":"hr001.docx","text":"Chunk 的文字內容,會以u524D","vector_provider":"AI.OpenAI.OpenAITextEmbeddingGenerator","vector_generator":"__","last_update":"2025-03-07T06:20:04"}', embedding=N'[Embeddings 值, 如0.01507735,0.013598721]', tags=N'{"__document_id":["hr001"],"__file_type":["application/..."],"__file_id":["6ecf..."],"__file_part":["11c5..."],"__part_n":["0"],"__sect_n":["0"]}'WHEN NOT MATCHED THENINSERT ([id], [key], [collection], [payload], [tags], [embedding])VALUES (NEWID(), N'd=hr001//p=每段的Id', N'gss', N'{"url":"","schema":"20231218A","file":"hr001.docx","text":"Chunk 的文字內容,會以u524D","vector_provider":"AI.OpenAI.OpenAITextEmbeddingGenerator","vector_generator":"__","last_update":"2025-03-07T06:20:04"}', N'{"__document_id":["hr001"],"__file_type":["application/..."],"__file_id":["6ecf..."],"__file_part":["11c5..."],"__part_n":["0"],"__sect_n":["0"]}', N'[Embeddings 值, 如0.01507735,0.013598721]');--將每個 Embedding 存到 KMEmbeddings_gss 中MERGE [dbo].[KMEmbeddings_gss] AS [tgt]USING (SELECT[dbo].[KMMemories].[id],cast([vector].[key] AS INT) AS [vector_value_id],cast([vector].[value] AS FLOAT) AS [vector_value]FROM [dbo].[KMMemories]CROSS APPLYopenjson(N'[Embeddings 值, 如0.01507735,0.013598721]') [vector]WHERE [dbo].[KMMemories].[key] = N'd=hr001//p=每段的Id'AND [dbo].[KMMemories].[collection] = N'gss') AS [src]ON [tgt].[memory_id] = [src].[id] AND [tgt].[vector_value_id] = [src].[vector_value_id]WHEN MATCHED THENUPDATE SET [tgt].[vector_value] = [src].[vector_value]WHEN NOT MATCHED THENINSERT ([memory_id], [vector_value_id], [vector_value])VALUES ([src].[id],[src].[vector_value_id],[src].[vector_value] );DELETE FROM [tgt]FROM [dbo].[KMMemoriesTags_gss] AS [tgt]INNER JOIN [dbo].[KMMemories] ON [tgt].[memory_id] = [dbo].[KMMemories].[id]WHERE [dbo].[KMMemories].[key] = N'd=hr001//p=每段的Id'AND [dbo].[KMMemories].[collection] = N'gss';--把Tags存到 KMMemoriesTags_gssMERGE [dbo].[KMMemoriesTags_gss] AS [tgt]USING (SELECT[dbo].[KMMemories].[id],cast([tags].[key] AS NVARCHAR(MAX)) COLLATE SQL_Latin1_General_CP1_CI_AS AS [tag_name],[tag_value].[value] AS [value]FROM [dbo].[KMMemories]CROSS APPLY openjson(N'{"__document_id":["hr001"],"__file_type":["application/..."],"__file_id":["6ecf..."],"__file_part":["11c5..."],"__part_n":["0"],"__sect_n":["0"]}') [tags]CROSS APPLY openjson(cast([tags].[value] AS NVARCHAR(MAX)) COLLATE SQL_Latin1_General_CP1_CI_AS) [tag_value]WHERE [dbo].[KMMemories].[key] = N'd=hr001//p=每段的Id'AND [dbo].[KMMemories].[collection] = N'gss') AS [src]ON [tgt].[memory_id] = [src].[id] AND [tgt].[name] = [src].[tag_name]WHEN MATCHED THENUPDATE SET [tgt].[value] = [src].[value]WHEN NOT MATCHED THENINSERT ([memory_id], [name], [value])VALUES ([src].[id],[src].[tag_name],[src].[value]);
COMMIT;
到了這裡,就已經將文件轉成 Embeddings 並存到 Vector DB(這裡是MSSQL), 再來就可以提供給使用者進行 RAG 問答
從 kmClient.AskStreamingAsync(question, minRelevance: 0.7, options: new SearchOptions { Stream = true }, index: tenantId) 開始,先將問題轉成 Embeddings ,再到資料庫找出相似度大於0.7的 Chunks 資料,查詢的 Script 如下,
WITH
[embedding] as
(SELECTcast([key] AS INT) AS [vector_value_id],cast([value] AS FLOAT) AS [vector_value]FROMopenjson(N'[問題的 Embeddings, 例如 0.008542997,0.012275496]')
),
[similarity] AS
(SELECT TOP (100)[dbo].[KMEmbeddings_gss].[memory_id],SUM([embedding].[vector_value] * [dbo].[KMEmbeddings_gss].[vector_value]) /(SQRT(SUM([embedding].[vector_value] * [embedding].[vector_value]))*SQRT(SUM([dbo].[KMEmbeddings_gss].[vector_value] * [dbo].[KMEmbeddings_gss].[vector_value]))) AS cosine_similarity-- sum([embedding].[vector_value] * [dbo].[KMEmbeddings_gss].[vector_value]) as cosine_distance -- Optimized as per https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-useFROM[embedding]INNER JOIN[dbo].[KMEmbeddings_gss] ON [embedding].vector_value_id = [dbo].[KMEmbeddings_gss].vector_value_idINNER JOIN[dbo].[KMMemories] ON [dbo].[KMEmbeddings_gss].[memory_id] = [dbo].[KMMemories].[id]WHERE 1=1GROUP BY[dbo].[KMEmbeddings_gss].[memory_id]ORDER BYcosine_similarity DESC
)
SELECT DISTINCTJSON_VALUE(payload, '$.text') AS Txt,[dbo].[KMMemories].[id],[dbo].[KMMemories].[key],[dbo].[KMMemories].[payload],[dbo].[KMMemories].[tags],[similarity].[cosine_similarity]
FROM[similarity]
INNER JOIN[dbo].[KMMemories] ON [similarity].[memory_id] = [dbo].[KMMemories].[id]
WHERE[cosine_similarity] >= 0.7
ORDER BY [cosine_similarity] desc
查詢的結果如下,

程式就會把這些資料組成 Prompt 來回覆使用者,如下,
Facts:
==== [File:請假規則.docx;Relevance:89.3%]:
Chunk 1 的內容....
==== [File:請假規則.docx;Relevance:87.1%]:
Chunk 2 的內容....
==== [File:請假規則.docx;Relevance:87.0%]:
假日,不給給薪薪薪)。
Chunk 3 的內容...
==== [File:請假規則.docx;Relevance:86.6%]:
位為為為0.5小時。
Chunk 4 的內容...
======
Given only the facts above, provide a comprehensive/detailed answer.
You don't know where the knowledge comes from, just answer.
If you don't have sufficient information, reply with 'INFO NOT FOUND'.
Question: 請假6天,需要簽到那位主管核准? 要事前幾天請呢?
Answer:
所以最後就從 LLM 就依 Search 到的內容來得到結果,如下,
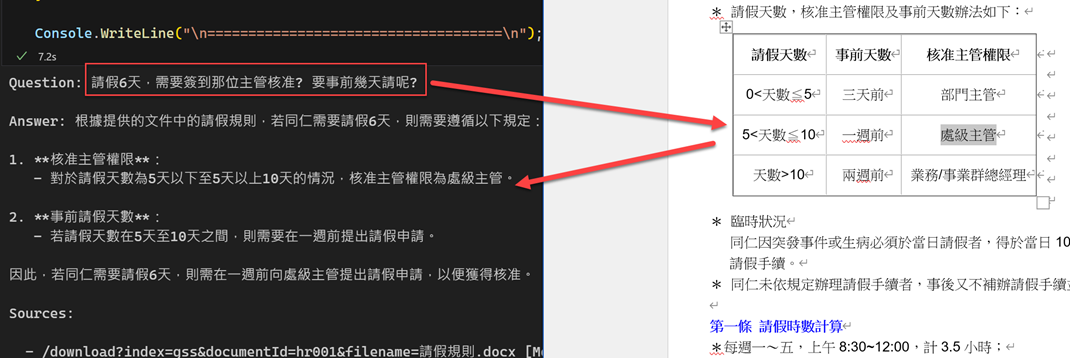
結論
embeddings 就是一堆的數值,比較難的是將文字計算出這些 embeddings,但許多 Embeddings Models 已經可以幫我們做到這些事。
所以我們可以將這些數值存到 Table 中,並建立 columnstore index 來加快它的查詢,然後計算出文字的相似度。
Cosine similarity [-1,1]的 SQL 如下,
SELECTSUM(a.value * b.value) / (SQRT(SUM(a.value * a.value)) * SQRT(SUM(b.value * b.value))) AS cosine_similarity
FROMvectors_values
數值越接近 1,代表兩個向量越相似。詳細請參考Vector Similarity Search with Azure SQL database and OpenAI
!!! 請注意,如果使用 MSSQL 建議使用 Azure SQL,或是等待 SQL 2025,使用 Vector 資料型態效能比較好,因為我用 LocalDB 來處理,常常會有 SQL Timeout 的狀況 !_!
參考資源
SQL 資料庫 引擎中的向量概觀
Vector Similarity Search with Azure SQL database and OpenAI
RAG with SQL Vector Store: A Low-Code/No-Code Approach using Azure Logic Apps
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
評論 7
好奇你的w2v是用openai的哪個模型
Hi Jaquan,
我是使用 e5-large 。
地端是用 e5-large, AOAI 是用 ada-002
哈哈! 謝謝回覆 ,不過我發現似乎最後的QA環節,RAG還是給了錯誤的回答(五天以下是要跟部門主管報告)
看來表格比起純文本還是很棘手的問題?
我測試起來都可以找到正確的答案說,可參考(https://www.gss.com.tw/blog/rag-kernelmemory-mssql)
不過,要先看用問題找到 Chunk 是否正確。
例如問題的長短,Chunk的大小,都會影響到 Search 的正確性。
另外在 多欄式 PDF + Table + 圖 & 圖例說明 真的是不好處理(目前可透過 Aspose 元件+程式處理),
最好還是在來源就先整理好,或是使用某手法增加 Chunk 的內容。
主要就是
1.讀取文件(知識庫) 要正確,
2.在產生 Chunk 前可依需求進行加值,例如產生 Q & A,Metadata,最後再加入 Summary
3.依文章段落決定 Chunk 的大小、例如每段大約只有200個Token,就不用切到500個Token
4.判斷使用者問題是否會太短,可適當地加入背景的內容或是跟問題相關的內容去進行 Search
...
所以依需求可以擴充所需要的 Kernel Memory Pipeline Handler 來處理
感謝
感覺pipeline出來了,但是每塊積木都還要尋找最佳解。XD
RAG還是給了錯誤的回答(五天以下是要跟部門主管報告) =>
這應該是 LLM 的問題,
找出的 Chunk 包含整個的 Table ,內容是用 0 Model 是 Phi4