GSS 技術部落格
在這個園地裡我們將從技術、專案管理、客戶對談面和大家分享我們多年的經驗,希望大家不管是喜歡或是有意見,都可以回饋給我們,讓我們有機會和大家對話並一起成長!
若有任何問題請來信:gss_crm@gss.com.tw
4 分鐘閱讀時間
(760 個字)
使用 Open Source 的 Kernel Memory 快速建立 RAG 服務

前言
[Kernel Memory]是 GitHub 上 Open Source 的軟體,可以讓我們快速建立 RAG(Retrieval-Augmented Generation)服務。
支持多種文件格式的文本(如 Image、Office、Pdf、Text 和 WebPages)的提取和分塊,並使用 LLM 嵌入生成器提取嵌入,將嵌入保存到 Vector DB 中。
文件處理到儲存到 Vector DB 的過程,是透過[DataPipeline]中的`Steps`來處理
。
,預設的 Pipleline 是 `PipelineStepsExtract, PipelineStepsPartition, PipelineStepsGenEmbeddings, PipelineStepsSaveRecords`,就是1.取得檔案內容,2.切 Chunks ,3.轉成嵌入,4.存到Vector DB
Vector DB 也可以存到`AzureAISearch`, `Qdrant`, `Postgres`, `Redis`, `SimpleVectorDb`及 `SqlServer` ...
當這些文件知識庫存到 Vector DB 後,使用者就可以透過 Filter 來進行 RAG 問答及摘要功能。
以下使用相容 OpenAI 的本地小模型(llama.cpp),並將嵌入保存到本地的 MSSQL 中。
實作
設定 Kernel Memory as a Service
參考[Kernel Memory as a Service],直接在本地運行。
在跑之前,要調整Service 專案中的`appsettings.json`檔案。
使用相容 OpenAI 的地端小模型(llama.cpp)並將嵌入保存到地端的 MSSQL,
`TextGeneratorType` 設定為 `OpenAI`
DataIngestion 區段,
`OrchestrationType` 設定成 `InProcess`,
`EmbeddingGenerationEnabled` 設定為 `true`,
`EmbeddingGeneratorTypes` 設定為 `[ "OpenAI" ]`,
`MemoryDbTypes` 設定為 `[ "SqlServer" ]`,
`TextPartitioning` 可以依需求去設定
Retrieval 區段,
`EmbeddingGeneratorType` 設定為 `OpenAI`
`MemoryDbType` 設定為 `SqlServer`
Services 區段中,
OpenAI 區段設定地端的 url 及 apikey,
"OpenAI": {
 "TextModel": "phi-4-q4",
"TextModel": "phi-4-q4",
"TextModelMaxTokenTotal": 16384,
"TextModelTokenizer": "",
"TextGenerationType": "Chat",
"EmbeddingModel": "e5-large",
"EmbeddingModelMaxTokenTotal": 500,
"EmbeddingModelTokenizer": "",
"APIKey": "sk-EA-xxx你的 apikey",
"OrgId": "",
"Endpoint": "https://地端的 URL/v1",
//...
}
"TextModel": "phi-4-q4","TextModelMaxTokenTotal": 16384,"TextModelTokenizer": "","TextGenerationType": "Chat","EmbeddingModel": "e5-large","EmbeddingModelMaxTokenTotal": 500,"EmbeddingModelTokenizer": "","APIKey": "sk-EA-xxx你的 apikey","OrgId": "","Endpoint": "https://地端的 URL/v1",//...}
SimpleFileStorage 區段中的 `StorageType` 改成 `Disk`
SqlServer 區段,設定 `ConnectionString`
設定好後,可以把程式跑起來,Console 的結果如下,
透過以上的設定,RAG Service 就完成了~
當然,您也可以執行 dotnet run setup 來透過詢問一步步地來設定 Config 值。
接下來透過 MemoryWebClient 這個類別,來將檔案上傳成為知識庫,並進行查詢來看看效果怎麼樣。
透過 MemoryWebClient 來操作
Kernel Memory Service 跑起來後,
再來就可以透過 MemoryWebClient 來將文件上傳成為知識庫,並進行問答
1.加入`Microsoft.KernelMemory` Nuget 套件
2.建立 MemoryWebClient Instance
using Microsoft.KernelMemory;
using System.Net.Http;
var kmServiceEndpoint = "http://localhost:5000/";
var httpClient = new HttpClient();
httpClient.Timeout = TimeSpan.FromMinutes(10);
var kmClient = new MemoryWebClient(kmServiceEndpoint, client:httpClient);
using System.Net.Http;
var kmServiceEndpoint = "http://localhost:5000/";
var httpClient = new HttpClient();
httpClient.Timeout = TimeSpan.FromMinutes(10);
var kmClient = new MemoryWebClient(kmServiceEndpoint, client:httpClient);
如果部署到正式環境,請記得調整 kmServiceEndpoint 的值。
3.呼叫`ImportDocumentAsync`來匯入文件
var docPath = @"C:\Projects\請假規則.docx";
var tenantId = "gss";
var documentId = "hr001";
await kmClient.ImportDocumentAsync(docPath, index: tenantId, documentId: documentId);
var tenantId = "gss";
var documentId = "hr001";
await kmClient.ImportDocumentAsync(docPath, index: tenantId, documentId: documentId);
註: documentId 可以讓它自動產生,或是指定一個值給它(最好給英數字,不要給中文哦~)
4.透過`IsDocumentReadyAsync`來查看是否匯入完成
var isDocReady = await kmClient.IsDocumentReadyAsync(documentId, tenantId);
if(isDocReady)
Console.WriteLine("Document ingestion is complete.");
else
Console.WriteLine("Document is not ready yet.");
if(isDocReady)
Console.WriteLine("Document ingestion is complete.");else
Console.WriteLine("Document is not ready yet.");5.進行RAG提問
var question = "請假6天,需要簽到那位主管核准? 要事前幾天請呢?";
Console.WriteLine($"Question: {question}");
Console.Write("\nAnswer: ");
var answerStream = kmClient.AskStreamingAsync(question, minRelevance: 0.7,
options: new SearchOptions { Stream = true }, index: tenantId);
List sources = [];
await foreach (var answer in answerStream)
{
Console.Write(answer.Result);
sources.AddRange(answer.RelevantSources);
await Task.Delay(5);
}
Console.WriteLine("\n\nSources:\n");
foreach (var x in sources)
{
Console.WriteLine(x.SourceUrl != null
? $" - {x.SourceUrl} [{x.Partitions.First().LastUpdate:D}]"
: $" - {x.SourceName} - {x.Link} [{x.Partitions.First().LastUpdate:D}]");
}
Console.WriteLine($"Question: {question}");
Console.Write("\nAnswer: ");
var answerStream = kmClient.AskStreamingAsync(question, minRelevance: 0.7,
options: new SearchOptions { Stream = true }, index: tenantId);List sources = [];
await foreach (var answer in answerStream)
{
Console.Write(answer.Result);sources.AddRange(answer.RelevantSources);await Task.Delay(5);}
Console.WriteLine("\n\nSources:\n");
foreach (var x in sources)
{
Console.WriteLine(x.SourceUrl != null? $" - {x.SourceUrl} [{x.Partitions.First().LastUpdate:D}]": $" - {x.SourceName} - {x.Link} [{x.Partitions.First().LastUpdate:D}]");}
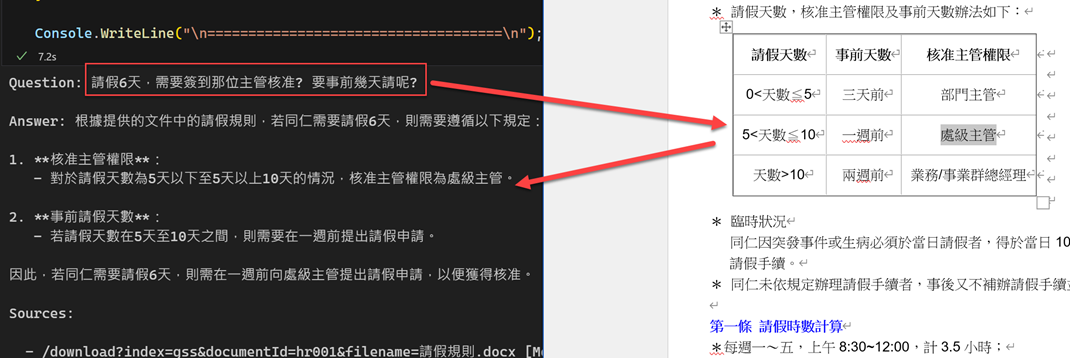
從上圖可以發現,可以從知識庫中找到對應的資訊並回覆給使用者
在單欄的 PDF Table 也可以查得到哦。
我查詢 7 月份的房價,是可以正常回覆的,如下,
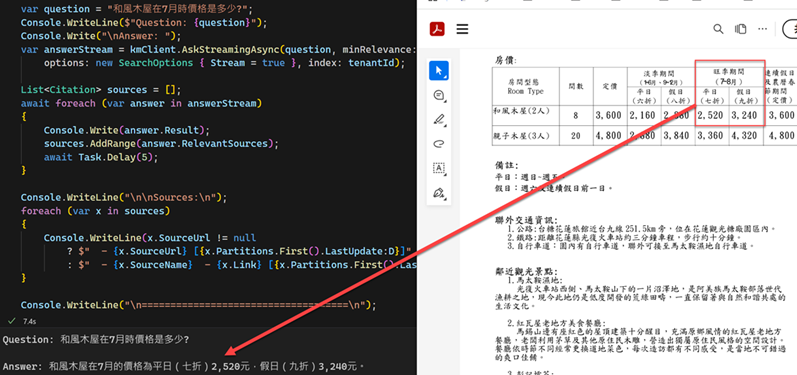
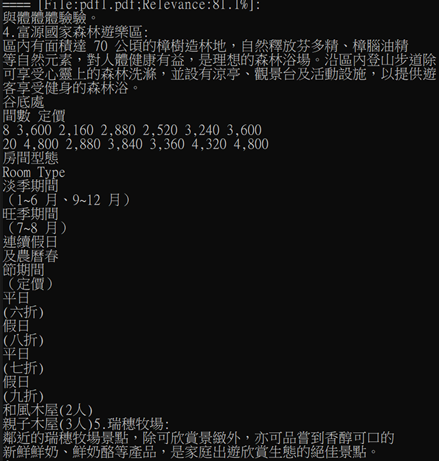
查到的 Chunk 資料如下(沒想到,這樣子的內容,LLM居然可以正常判斷!),
註: 在本機測試使用`OrchestrationType`為
InProcess 比較方便,如果是大檔或是正式機,請使用 DistributedStay Informed
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
評論