GSS 資安電子報 0235 期【當 AI 具備記憶,A2A 與 MCP 技術如何守住資安防線? 】
當 AI 具備記憶,A2A 與 MCP 技術如何守住資安防線?
在過去的一年中,我們見證了大型語言模型(LLMs)使用方式的重大轉變,它們不再只是靜態的助理,而是逐漸演化為能夠保留並回憶資訊的記憶型智慧助理。其中最具潛力的技術之一,是 Anthropic 推出的 Model Context Protocol(MCP)。不過,採用類似情境感知機制的並不只有 Anthropic,像是 Google 的 A2A 協定與 Gemini,以及 OpenAI 和 Copilot,也都正朝同樣的方向發展。
在本篇文章中,我們將深入探討:
- MCP、A2A 以及其他 Model Context Protocol(MCP)是什麼,以及它們為何重要?
- 各大平台如何實現類似的概念
- 使用代理情境協定所帶來的風險
- 在邁向未來的同時,如何有效保護自己
讓 AI 擁有記憶,究竟意味著什麼?
當我們談論為人工智慧導入記憶功能時,並不是指長期回憶或更完善的聊天紀錄,而是指從孤立的語言模型轉變為具備真實情境的嵌入式代理。像 MCP 和 A2A 這類技術,讓模型能直接整合到我們每天使用的系統、工具和環境中,從而實現這樣的可能性。
將行動執行階段保護視為策略性信任資產,而非僅是合規項目,能讓資安長更快速地取得高層支持。 簡而言之,如果您的行動應用程式在執行階段沒有受到保護,就是沒有保護好您的企業。將零信任原則融入行動應用程式執行階段,已成為企業的策略性當務之急。
直到最近,大多數語言模型都是獨立運作,「你給它們提示,它們回應你」,但它們沒有記憶、不了解你正在做什麼,也沒有連結到文字以外的任何資訊。而這種狀況正在迅速改變,現在,我們開始將模型連接到真實的情境來源:像是命令列指令、檔案系統、瀏覽器工作階段、HTTP 請求等等。這使得模型能理解周遭發生的事,對即時系統狀態做出反應,甚至影響其他工具。這種能力非常強大,但如果整合沒有做好安全控管,也可能帶來風險。
這些新介面帶來了全新的攻擊面,例如提示注入(prompt injection)不再只是讓模型說出奇怪的話,而是可能觸發真實操作,或洩漏模型原本不該接觸的敏感資料。當模型擁有對即時系統的讀寫權限時,任何一個漏洞都可能導致真實際的嚴重後果。
A2A 和 MCP 都致力於標準化模型存取情境資料的方式,但隨著標準化,也帶來了更高的風險暴露。作為防護者,我們必須開始用對待微服務的思維來看待模型:它們能接觸哪些資料?誰能與它們互動?有哪些防護機制?我們是否能審計模型的存取行為?是否具備限制範圍或動態撤銷存取權的控管措施?
為 AI 加入記憶功能是不可避免且非常有價值的發展,事實上,這正是最令人期待的應用場景。但資安議題才剛開始展開。如果現在不認真定義並落實界限,未來就會面臨許多原本可以避免的事件。
MCP 究竟是什麼?
Model Context Protocol(MCP)是透過標準化的 JSON 介面,將像是檔案、命令列輸出、資料庫狀態或使用者活動,這類結構化的真實情境資料提供給 AI 模型。MCP 讓工具能自動提供這些資訊,取代手動將資料嵌入提示,讓模型能用一致的方式理解並在環境中做出反應。
這為各種實際應用整合開啟了可能性。你可以將模型連接到 Gmail MCP 伺服器,讓它在回答問題時參考特定的郵件;也可以透過 MCP 伺服器連接到本地開發環境,讓它提供目前開啟的檔案、執行中的任務或 git 資訊。幾乎所有你能想到的情境,都有對應的 MCP 伺服器。官方的 MCP 伺服器集合提供了實際運作的範例,從 Docker 整合、HTTP 請求檢查,到檔案系統探索和 SQLite 查詢等都有涵蓋。關鍵不在模型獨自的能力,而是在於它能夠在受控且安全的環境下,結合並運用你的實際環境所帶來的價值。
在 MCP 架構中,主機(hosts)是發起連線的大型語言模型應用程式;客戶端(clients)是嵌入在主機內的連接器;而伺服器(servers)則負責提供情境資訊或功能。
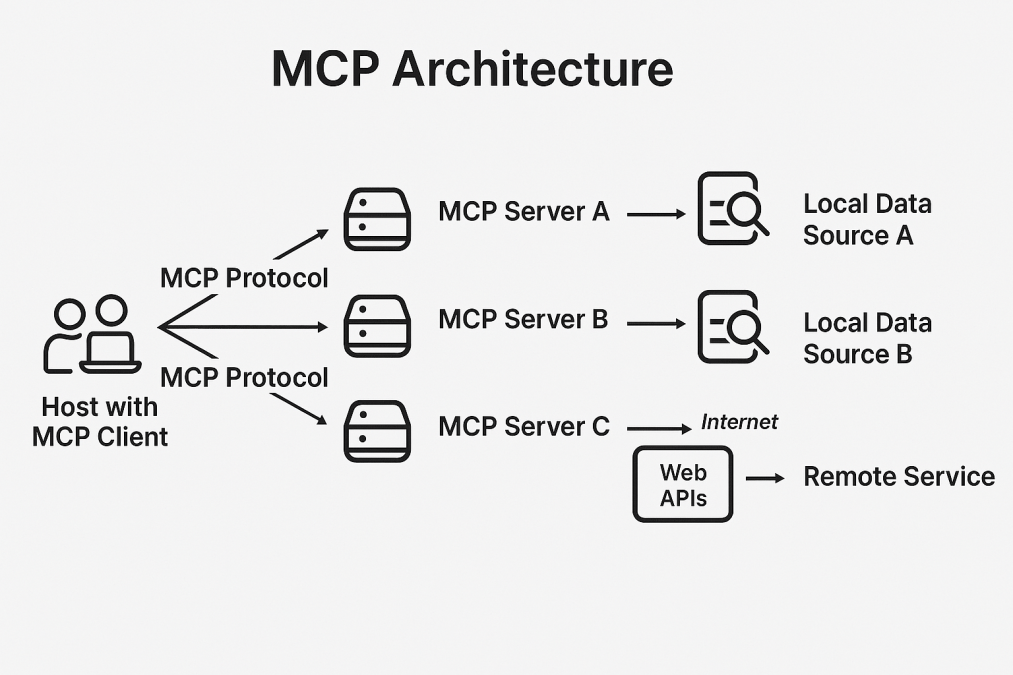
為了理解 MCP 的運作方式,先釐清幾個重點:MCP 客戶端是面向使用者的應用程式,負責發起請求並顯示結果;而 MCP 伺服器則是中介系統,處理請求、管理與各種資料來源的連線,並依照標準協定將整理後的資訊回傳給客戶端。
如圖所示,使用者系統上的 MCP 客戶端可以同時與多個 MCP 伺服器(A、B、C)進行通訊,每個伺服器負責不同的功能。各伺服器與其各自的本地資料來源互動,提供本地及遠端資訊的存取。這種架構讓客戶端能透過統一協定,存取多元的資料來源和服務,打造出兼具彈性與擴展性的網路,平衡地端資料處理與雲端資源的運用。
Google 的 Agent to Agent(A2A)協定
Google 最近推出了 A2A 協定,作為跨平台 AI 代理之間進行安全且結構化溝通的開放標準。雖然目前仍處於早期階段, Google 將這項協定作為開放標準提案,旨在讓不同平台的代理能夠運用常見的網路技術,安全地協同合作與交流。
根據 Google 敘述,A2A 是一種與 Anthropic 的 Model Context Protocol(MCP)互補的開放協定。MCP 著重於為代理提供實際工具與真實情境的存取能力,而 A2A 則打造一個安全的協作框架,使不同代理能夠跨平台共享資訊並合作,進而將原本孤立的系統整合成一個更具連結性與協同效能的 AI 生態系統。
資料來源:Google A2A 協定公告
A2A 提供一個框架,讓 AI 代理能透過 HTTPS 傳遞 JSON 格式的資料。這個框架支援身份驗證、權限控管以及負載簽章機制,確保代理之間的信任與安全性。
透過新的 A2A 協定,代理可以彼此請求協助,例如請另一個代理安排會議、取得資料或執行工作流程,而無需了解該代理的具體實作方式。代理在協作時能夠傳遞相關情境資訊(如記憶、使用者偏好或目標),讓後續代理能夠有智慧地執行任務,而不用從頭開始。
此外,標準 Gemini 也包含一些類似 MCP/A2A 的概念,並整合了多項情境感知功能:
- Gemini 能整合 Gmail、Docs 和行事曆,取得即時資料:Gemini 可連接並從 Google Workspace 應用程式如 Gmail、Docs 和行事曆擷取資訊,讓它能存取「即時資料」,處理這些服務的最新資訊,用來回答問題、摘要內容或協助完成任務。
- 「擴充功能」讓 Gemini 可查詢第三方工具如 YouTube 或 Google Flights:Gemini 支援使用「擴充功能」與第三方服務互動,例如 YouTube、Google Flights 等。
- Gemini 的 App Actions 支援在 Android 應用程式內進行結構化互動,類似 MCP/A2A 的功能呼叫:Android 的 App Actions 讓使用者(以及可能的 AI 模型)能以更直接且結構化的方式,操作 Android 應用程式內的特定功能。
OpenAI 的代理情境功能
雖然 OpenAI 尚未完全整合新的 MCP 協定或推出自有版本,但他們已開始推出多項功能,讓情境運用更加完善,例如:
- 自訂具記憶功能的 GPT:當你透過 ChatGPT 創建自訂 GPT 時,它能跨多次對話記住使用者的資訊,包括偏好、姓名、寫作風格或目標,你也可以查看並刪除這些記憶。
- ChatGPT 記憶功能:一般版 ChatGPT 也支援記憶功能,助理可以記住你喜歡簡潔回覆,或你是使用 Python 的程式設計師,讓對話更貼近個人化,減少重複說明。
- 工具、功能呼叫與檢索器(RAG):類似 MCP,這些元件現在可以協同運作,例如:
- 模型能呼叫 API 查詢你的行事曆
- 搜尋向量資料庫取得相關知識(檢索器)
- 結合這些資訊與記憶,做出更符合需求的回應
GitHub 的 Copilot
GitHub 是最早開始支援 MCP 的平台之一,現在已經有專用的 GitHub MCP 伺服器,讓使用者可以更方便地存取資料、整合功能。
那 Copilot 呢?你可以像連接其他 MCP 客戶端一樣,將 MCP 伺服器連接到 Copilot,但 Copilot 本身也內建了一些類似 MCP 行為的功能,值得注意:
- 當地情境感知:Copilot 主要是依據你目前開啟的檔案、資料夾結構,以及最近的編輯內容,來提供建議。它會根據你正在處理的程式碼,建立一個「暫時性的情境視窗」。
- 專案範圍索引:在 Copilot for Business 和 Copilot Chat 中,它能索引並參考整個 repo 裡的其他檔案,不只限於目前編輯的檔案,有點類似短期記憶的效果。
- Copilot 工作空間(即將推出):GitHub 預告了一項新功能叫 Copilot Workspace,能讓你在整個 repo 裡規劃與執行任務。這項功能未來可能會進一步發展成具備記憶、會持續追蹤狀態的智慧代理,也可能會導入類似 MCP 的情境共享機制。
AI 系統中情境共享與代理通訊的資安風險
就像多數 AI 領域的新概念一樣,這些功能帶來的好處相當吸引人,但如果沒妥善處理,也會伴隨實質的風險。
這些技術的確令人期待,也非常實用,但同時也帶來一些資安上需要特別注意的風險。
1. 資料外洩風險
給大型語言模型的情境資訊越多,它的回應就越有幫助,但相對地,一旦模型本身或其周邊環境被攻擊,所暴露的風險也會隨之增加。我們提供的資料越多,攻擊者能掌握的資訊就越多。
這在代理架構的環境中更是明顯,因為情境資訊是動態地在工具或服務間流動的。攻擊者甚至不需要直接入侵模型本身,只要攻破其中一個提供資料的服務,就可能取得敏感資訊。
2. 設定錯誤與過度暴露風險
和所有部署在雲端的服務一樣,若不慎將服務暴露在公開網路上,風險相當高。舉例來說,為了方便測試,開發者可能會把本地 MCP 伺服器綁定到 0.0.0.0,但這樣可能會不小心讓 /v1/context 端點暴露在網路上。這個端點通常用來提供豐富且結構化的情境資料給大型語言模型,一旦開放給未授權的模型或服務,就可能導致敏感資訊外洩。
在 A2A 類型的環境中風險更大,因為代理彼此會透過公開協定尋找並溝通。一個設定錯誤的端點可能無意間將內部情境暴露給未授權的同儕,或冒充可信代理的攻擊者。若缺乏嚴格的存取控管和適當的權限範圍管理,哪怕是一個小小的設定失誤,都可能讓攻擊者取得專案目錄、使用者元資料或系統內部資訊,將原本簡單的疏忽變成嚴重的安全漏洞。
3.供應鏈攻擊風險
許多類似 MCP 的應用場景會用到外掛、擴充功能或外部工具,例如整合開發環境(IDE)、終端機或瀏覽器,這些工具會寫入或影響模型的情境資料。如果惡意或被入侵的擴充功能能修改模型的情境,就可能破壞模型對工作環境的判斷,甚至洩漏私人資訊。
當使用一些現成的外掛程式或社群開發的整合工具時,資安風險會更高,因為這些工具通常只會留下最少量的稽核軌跡資訊,導致後續追查困難。像是會把情境資訊同步到 MCP 或 A2A 代理的瀏覽器擴充功能或開發工具(IDE)插件。
4.資料投毒風險
就像其他大型語言模型所依賴的資料來源一樣,從外部取得的情境資料也可能被操弄,特別是當這些資料是由其他系統、第三方 API 或外掛所寫入時。如果模型是根據這些資料來做判斷或執行操作,那麼一旦資料被投毒或遭到竄改,就有可能導致模型回應錯誤、行為異常,甚至執行一些原本不該發生的動作。
舉例來說,若你使用 MCP 來讀取和撰寫電子郵件,攻擊者(或惡意內部人員)可能故意寄出內容錯誤、垃圾訊息或帶有誤導性的郵件,讓模型在理解這些內容時產生偏誤。在 A2A 的情境中,某個惡意代理甚至可以污染共用的狀態資料,或將誤導性的情境注入其他代理的工作空間,讓模型基於錯誤的前提做出判斷,或在沒有被操控提示的情況下產生有害結果。
5.跨工具污染風險
當一個代理(如 LLM)同時連接到多個代理、伺服器或應用程式(例如 Gmail、Slack、GitHub)時,只要其中一個出現惡意行為,就可能影響整個環境的整體安全性。
舉例來說,如果某個 MCP 伺服器被入侵,攻擊者就可能藉此控制模型,讓它去與其他伺服器互動,進一步擴大攻擊範圍。在 A2A 的協作模型中,這類風險會更明顯,因為代理彼此之間的信任邊界往往定義不清,任何一個被攻破的元件都可能成為跳板,發動針對整個系統的間接攻擊。
如果缺乏明確的隔離機制與授權控管,攻擊者在系統中的橫向移動不僅變得可行,甚至很可能發生。
6.提示注入
最終,我們必須正視一個事實:允許模型存取我們無法完全掌控的外部資料來源,本身就存在高度風險。這些資料來源有可能已經被攻擊者掌控,而他們知道模型會連接到這些來源,便藉機在資料中夾帶隱藏指令,透過 MCP、外掛、或其他代理等管道,對模型發動提示注入攻擊。
這類風險在實際案例中也曾發生,例如 WhatsApp 的 MCP 被濫用事件中,攻擊者就是將惡意內容注入情境欄位,導致模型執行了原本不該發生的操作。
這樣的問題不僅存在於單一模型的情境連接,在 agent-to-agent 的通訊架構中也同樣適用。只要有任一代理能注入任意情境或操作提示,並經由共享記憶傳遞出去,就有可能接管其他下游代理的行為與決策流程。
7.遠端程式碼執行 (RCE)
我們前面提到的一些工具或實作方式中包含了「可呼叫的功能」,讓 LLM 可以根據情境主動觸發這些功能。例如,模型可能會自動撰寫電子郵件或啟動部署流程。若攻擊者能入侵模型,或是操控這些工具的定義,就可能透過誘導模型呼叫帶有惡意參數的函式,進一步升級為遠端程式碼執行(RCE)攻擊。
這類風險在模型擁有高度自主權的環境中尤其危險,因為一旦成功誘導,就可能讓攻擊者間接控制整個系統。
8. 驗證機制設計不佳
起初,MCP 並沒有統一的驗證標準。後來的版本才將 OAuth 2.1 流程(例如發行與驗證 Token)直接內嵌在 MCP 伺服器中。這樣的設計違反了身份驗證與資源管理應該分離的原則,不僅增加了系統運作的複雜度,也擴大了協定的攻擊面。
在代理對代理的架構中,如果驗證流程範圍設定不當,可能導致代理信任錯誤的同儕,或接受未授權來源的 Token,進而引發資料外洩、冒名頂替或權限升級等嚴重資安問題。
代理情境協定的資安最佳實務
那麼,我們該如何善用這些強大的功能,同時確保環境安全呢?
以下是幾項能降低使用代理情境協定風險的最佳實務建議:
1.減少網路暴露
使用 MCP 伺服器或類似 A2A 的解決方案時,務必嚴格設定網路存取政策,確保只有必要的通訊埠開啟,且只有受信任的實體能存取協定環境中的資源。除非必要,避免將重要端點暴露於公開網路;若必須公開,務必實施強化驗證、TLS 加密以及零信任網路分段。
2.強制情境資料驗證與消毒
將外部情境資料視為敏感輸入,務必對所有情境負載進行驗證,剔除不必要或不安全的內容,且禁止未受信任或使用者可控的程序直接寫入。如此可防止潛在的注入攻擊、資訊外洩或模型操控。
3.驗證機制
強制使用強而有力的 Token 驗證非常重要。請確保憑證安全存放、定期更換,且權限設定維持在最低必要範圍。系統設計應讓代理情境協定的伺服器驗證由您現有身份提供者(IdP)所發出的 Token,並可選擇使用 API Gateway 來負責驗證與安全地傳遞身份資訊。
在 MCP 伺服器中,當遇到未授權的請求時,應回傳 WWW-Authenticate 標頭,指引用戶端導向正確的授權伺服器,這也是 MCP Issue #205 中所建議的做法。
4.監控並記錄情境端點的存取狀況
無論是代理間通訊還是代理與伺服器之間的互動,都應該全面監控並記錄所有請求與流量,方便追蹤誰在什麼時候存取了哪些資料,並及早發現異常行為。
5.採用最小權限原則分享情境資料
只分享絕對必要的內容:
- 避免傳送整個編輯器狀態、整個資料夾或無關的使用者元資料(metadata)
- 在使用 IDE 整合或自動化代理時,確保明確過濾分享的內容
- 優先採用細緻的資料遮蔽與權限範圍控管
6.確保供應鏈安全
確保所有能存取模型的組件與相依套件皆來自可信來源且持續更新,並隨時留意新出現的相關漏洞。
未來展望:邁向以代理為導向的 AI
代理情境協定標準的出現,代表著一場重要的轉變:
- 從聊天到記憶:代理不再每次對話都從零開始,而是能夠保存你平常的需求與偏好,像 OpenAI 所做的記憶功能一樣。
- 從提示詞到協定:應用程式開發者將從脆弱的提示詞設計,轉向結構化的情境架構,能更精準地讓大型語言模型回應使用者的需求。
- 跨平台整合:使用者能同時依據多個資料來源獲得結果,並存取目前大型語言模型或生成式 AI 資料庫中沒有的個人資料。
- 集中式控管:這些新發展將推動助理型應用程式的誕生:MCP、A2A 以及未來類似的技術,讓我們能用單一平台控管多個應用並執行任務。
我們正站在「大型語言模型作業系統」的分水嶺,每個應用都擁有自己的記憶、情境和工具鏈,並隨著時間持續進化。
結語
這些代理情境協定不只是協定本身,更是智慧系統未來的藍圖。Anthropic 與 Google 領先推出標準化的情境載入架構,其他平台也在同時以各自方式跟進。
但如同所有協定一樣,細節決定成敗。當你標準化了一種暴露敏感情境的方式,也同時標準化了可能被濫用的途徑。
資安團隊必須提前準備,MCP、A2A 等相關技術將會無處不在,無論是在 IDE、終端機,甚至瀏覽器擴充功能中。越早建立起「安全預設(secure-by-default)」的思維,就越能有效防範未來的風險。
Orca Security 如何提供協助?
無需安裝 Agent,即可快速整合 AWS、Azure、Google Cloud 等多雲環境,深度掃描雲端工作負載、儲存體、容器、Kubernetes、身份與存取管理(IAM)等,全面掌握雲端資產的安全狀況。Orca Security 採用創新的 SideScanning™ 技術,可偵測惡意程式、設定錯誤、過高權限、API 漏洞與合規性問題,減少雲端攻擊風險。此外,系統運用 AI 分析,智慧化評估並優先處理最具威脅性的安全風險,確保團隊不會因過量警報而忽略真正的危機。Orca Security 亦內建即時合規監測功能,支援 CIS、NIST、ISO 27001、GDPR 等國際安全標準,幫助企業符合監管要求。透過完整可視性與精準風險分析,Orca Security 讓 DevOps、SecOps 及 IT 團隊能更有效率地發現與修復雲端環境中的安全漏洞,提升整體安全韌性。
- 無需 Agent,100% 覆蓋雲端資產
- 優先級告警,確保合規與風險可視性
- SDLC 全面防護,強化開發安全
- 無縫整合工作流程,提升團隊協作與效率