決策樹(Decision tree)屬於機器學習中監督式學習的演算法,該演算法的優點包含:易理解、短時間有較佳的預測結果且容易解釋分析結果等,故為常見且具代表性的監督式學習演算法之一。決策樹的建立過程會建立一個樹狀的結構,其結構由根結點、子結點以及葉結點所組成,較為常見的決策樹演算法包含:CART、ID3、C4.5、C5.0等。
以下透過R語言來進行實踐:以iris鳶尾花的資料集為例。
> head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
> n <- nrow(iris) > test_percent <- 0.1 > test_n <- floor(n*test_percent) > set.seed(123) > test_index <- sample(1:n,test_n) > test_data <- iris[test_index,] > train_index <- seq(n)[-test_index] > train_data <- iris[train_index,] > library(rpart) > #使用Sepal.Length、Sepal.Width、Petal.Length、Petal.Width 預測 Species,建立分類決策樹 > iris_tree <- rpart(Species ~ .,method = "class",data = train_data) > #summary(iris_tree) #模型詳細資訊
為方便觀察決策樹,以下我們透過4種不同方式的方式繪之。
1.R內建plot指令。
2.套件:rpart.plot、函式:prp。
3.套件:partykit 、函式: plot。
4.套件:rattle、函式:fancyRpartPlot。
> plot(iris_tree);text(iris_tree)

> library(rpart.plot) > prp(iris_tree,faclen=0,fallen.leaves=TRUE,shadow.col="gray",extra=2,cex = 1)
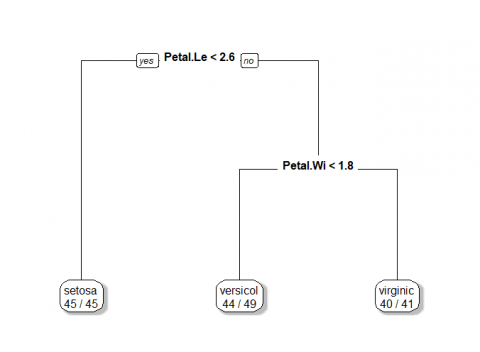
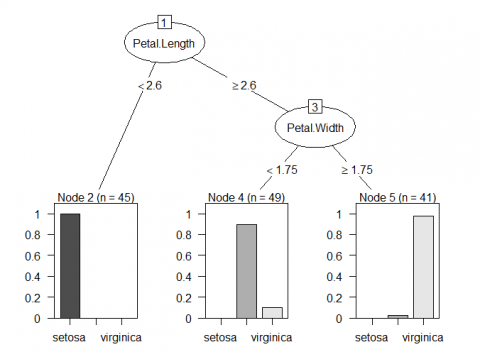
> library(partykit) > plot(as.party(iris_tree),cex = 1)
> library(rattle) > fancyRpartPlot(iris_tree,sub = "",cex = 1)
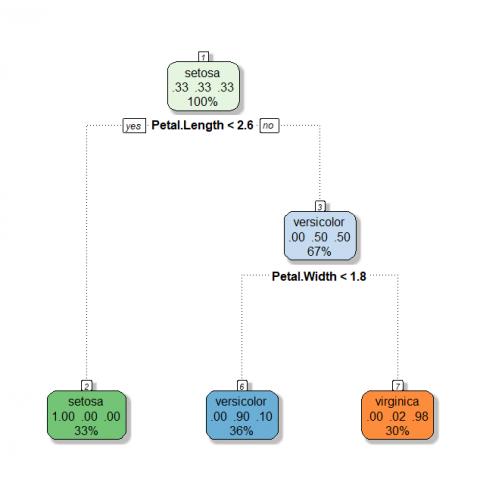
由圖可知,第一種透過R內建的plot所畫出的決策樹,僅能觀察到決策樹的判斷方式與結果,第二種透過套件rpart.plot所畫出的決策樹,雖較第一種美觀但能呈現的訊息依然有限,而第三種透過套件partykit所畫出的圖形,其優點在於葉節點透過可透過長條圖看到訓練集分布狀況,而第四種透過套件rattle所畫出的各節點,會透過不同色系進行呈現,以上圖為例,由於Species種有三類,故共有3種色系,且顏色越強烈則分類效果越佳,當我們只關心某一種類型的分類結果是如何進行判斷時,該圖形便能一目了然找出判斷路徑,故筆者更常使用第三種或第四種方式進行呈現。
接著我們透過函示predict進行預測,並使用混淆矩陣檢視訓練集與測試集準確率。
> ##train準確率
> Species_train <- iris$Species[train_index]
> (train_table <- table(train = iris$Species[train_index],predict = predict(iris_tree, newdata=train_data, type="class")))
predict
train setosa versicolor virginica
setosa 45 0 0
versicolor 0 44 1
virginica 0 5 40
> sum(diag(train_table))/sum(train_table)
[1] 0.9555556
>
> ##test準確率
> (test_table <- table(test = iris$Species[test_index],predict = predict(iris_tree, newdata=test_data, type="class")))
predict
test setosa versicolor virginica
setosa 5 0 0
versicolor 0 5 0
virginica 0 0 5
> sum(diag(test_table))/sum(test_table)
[1] 1
結果顯示,訓練集以及測試集的準確率分別為95.6%、100%,若我們要更進一步的優化決策樹,則可透過函示rpart.control進行優化,其中較經常使用到的參數包含:
minsplit:建立新的節點最少需要幾筆資料。
minbucket:建立新葉節點最少需要幾筆資料。
cp:複雜度的參數,通常選擇xerror(交叉驗證的估計誤差)最小的cp。
maxdepth:樹的深度。
> iris_tree$cptable
CP nsplit rel error xerror xstd
1 0.5000000 0 1.00000000 1.2555556 0.04768054
2 0.4333333 1 0.50000000 0.6888889 0.06433509
3 0.0100000 2 0.06666667 0.1111111 0.03381003
> iris_tree_fix <- rpart(Species ~ .,method = "class",data = train_data,control = rpart.control(minsplit = 10,cp = 0.001,maxdeptth = 30))
>
> ##train準確率
> (train_table_fix <- table(train = iris$Species[train_index],predict = predict(iris_tree_fix, newdata=train_data, type="class")))
predict
train setosa versicolor virginica
setosa 45 0 0
versicolor 0 42 3
virginica 0 1 44
> sum(diag(train_table_fix))/sum(train_table_fix)
[1] 0.9703704
>
> ##test準確率
> (test_table_fix <- table(test = iris$Species[test_index],predict = predict(iris_tree_fix, newdata=test_data, type="class")))
predict
test setosa versicolor virginica
setosa 5 0 0
versicolor 0 5 0
virginica 0 0 5
> sum(diag(test_table_fix))/sum(test_table_fix)
[1] 1
經過rpart.control略微調整後,此時測試集的準確率略為提升至97%。
以上為透過R的rpart套件示範決策樹的的建立過程,雖然決策樹的有諸多優點,然而在實務上則需要不斷的調整樹的各種參數,才會獲得較佳的決策樹結果。
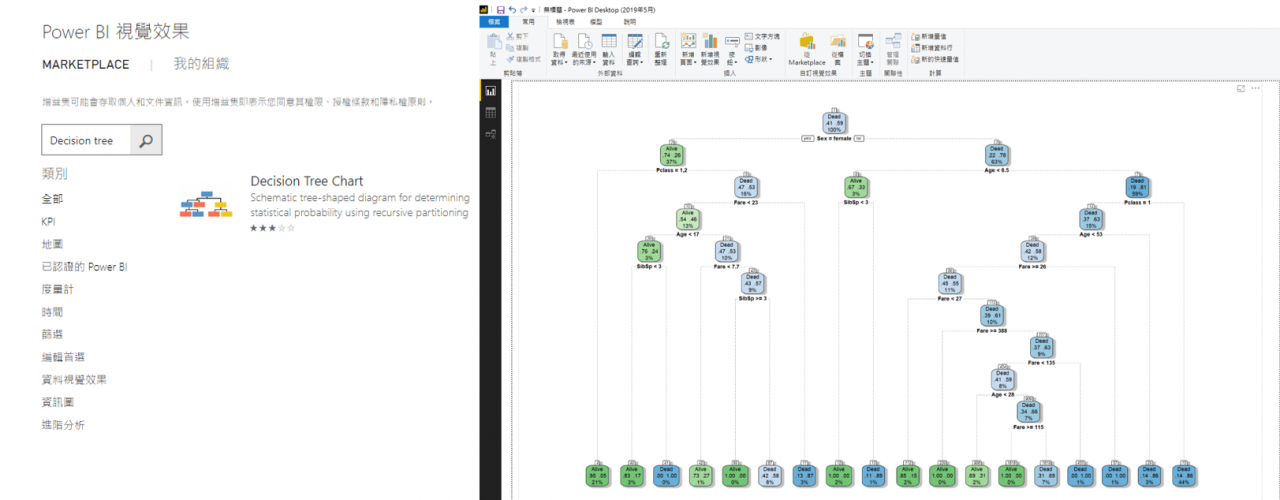
最後,若您也有使用微軟的Power BI進行數據分析,該工具提供了Decision Tree Chart 視覺化效果可進行決策樹分析,其中便包含使用到了R的rpart以及rpart.plot等套件,可使得決策樹的建立更加方便容易。