若有任何問題請來信:gss_crm@gss.com.tw
R語言資料視覺化技巧-facet-多類別資料分析
前言
今天要來講資料視覺化的工具-R語言的ggplot
在做資料科學的研究時,基本上不會想要也沒有必要使用傳統的for迴圈操作資料
常見的工具如python的numpy+pandas,data本身型態就是iterable的
在R裡面資料結構本身就是向量化操作dataframe,讓你看不到for這個字
資料好操作是一回事,那畫圖呢? 基本上用傳統的Excel這種套裝軟體就可以畫。
但在巨量資料面前,套裝軟體的資料操作彈性低,視覺化的可擴展性也非常低,而且比較古老一點的工具會直接吃爆記憶體讓你動不了(我就很討厭Excel)。
ggplot在幾何構圖方面非常強大,在二維可視圖中,顏色、圖案形狀、圖案大小這些都可以當做資料維度,讓你在一張平面圖就可以看出超過二維的資料分析
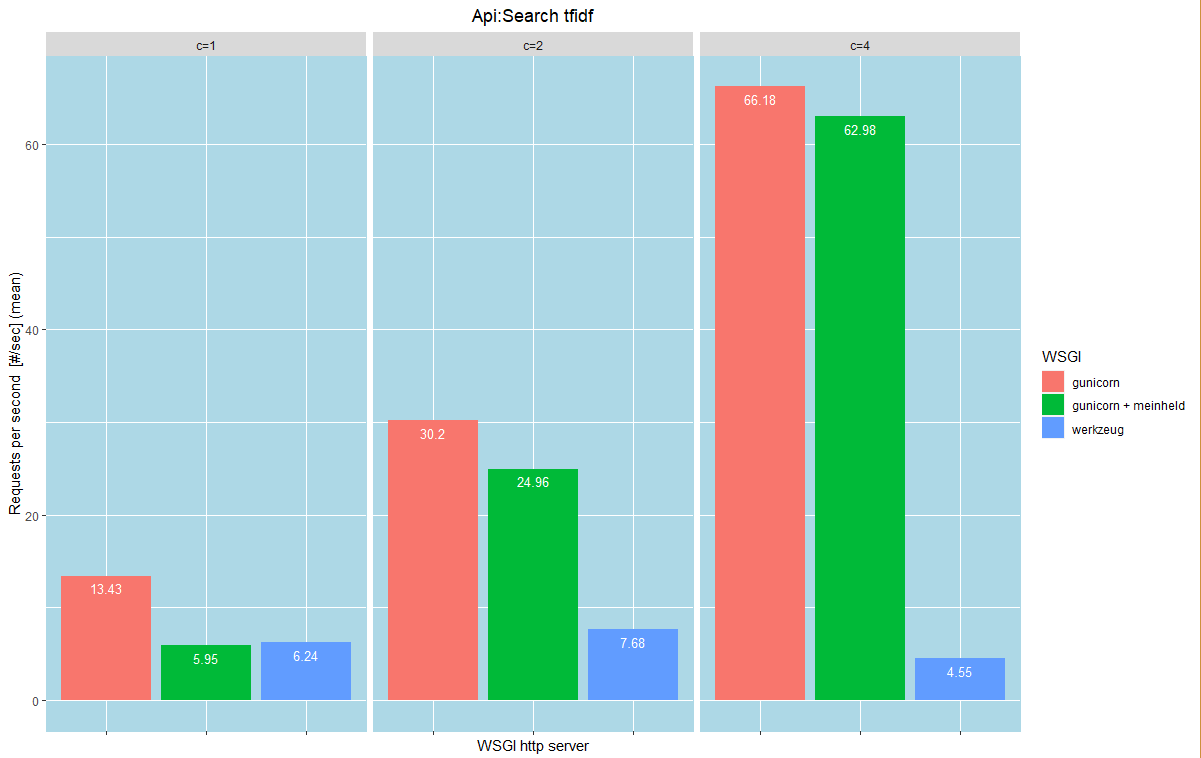
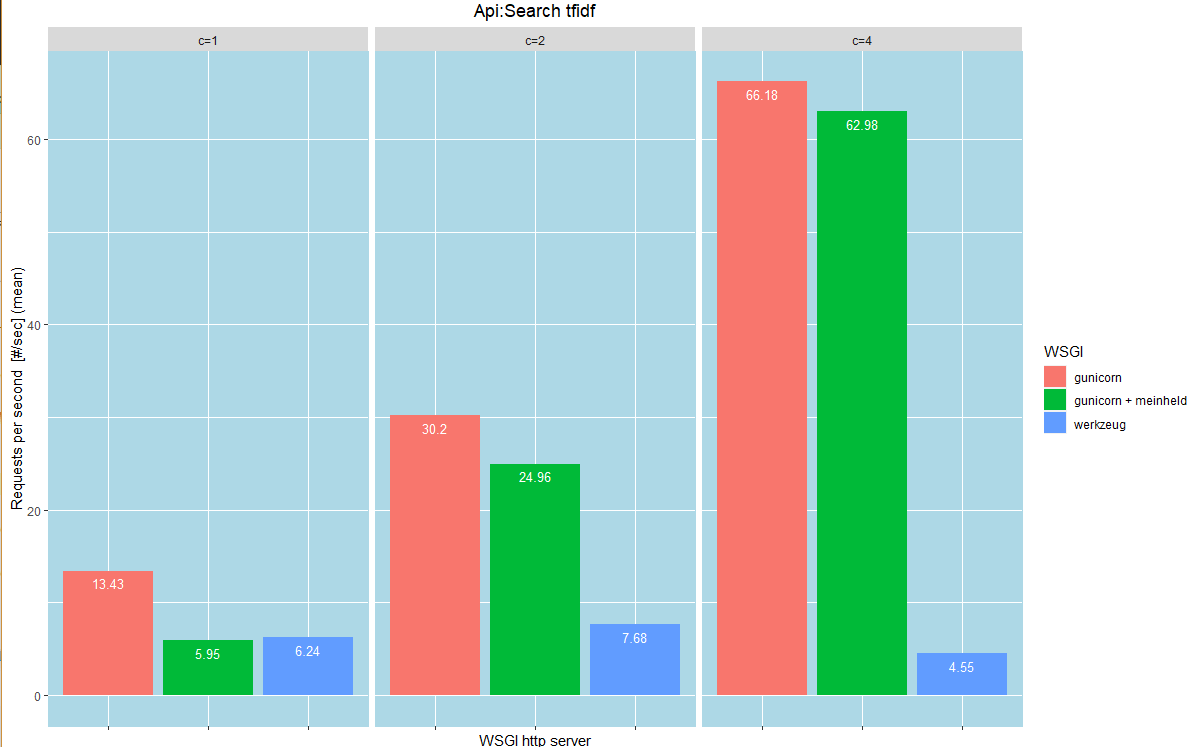
如上圖,是我們的分析結果,一張圖可以看出在c = 1,2,4下,三種WSGI每秒鐘可以請求的數量,不用畫三張二維圖來觀察在不同c下x對y的差異
以下我們會看到ggplot在視覺化方面的威力。
我們要來分析資料了,以下將我平常使用的分析技巧先簡單說明一下:
Step 1: 資料載入及觀察
Step 2: 資料前處理
Step 3: 資料視覺化
Step 4: 資料分析以及解釋
步驟確定,同樣的code寫完以後只要清理你的資料格式,就可以將不同領域資料呈現出多角度的分析內容: 就是code不太需要動,換資料就可以啦 !
接下來我們用R語言直接操作資料以及做視覺化分析
首先來看一下我們要分析的資料
Step 1: 資料載入及觀察
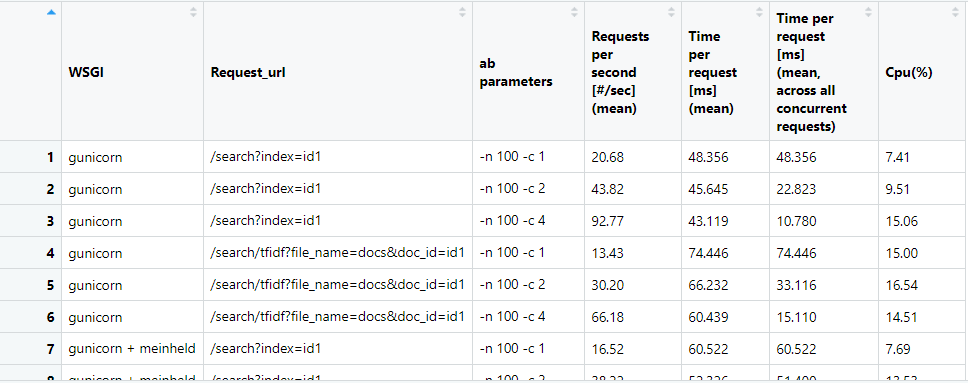
上圖是我用ab工具壓力測試以文找文的Api的結果,用R載入excel檔案後會在IDE(叫做Rstudio)上面呈現出dataframe(就是上圖)給你看
資料說明:
WSGI: 不同的python伺服器模組 ,有gunicorn、gunicorn + meinheld、werkzheug這三種方式啟動Api服務
ab parameters: n是傳送請求的總數量,c表示同時傳送的Api請求數量
Requests per second: 每秒鐘可以處理的Api請求數量,愈大愈好
簡單來說就是要看這三種WSGI的server每秒鐘可以處理的請求數量,誰比較多
並且選擇表現較好的server
install.packages("readxl") #安裝套件
library("readxl") #載入套件
data = read_excel("ab_result.xlsx" ) #讀檔
使用R的第三方套件 readxl
只要一行就可以讀檔拉
然後R直接在IDE就完成這三個動作,資料分析師請把你的時間省下來去做分析
readxl是一個超級overload的function
要設定encoding、忽略空值、設定欄位名稱、限制讀入行數、跳過讀入行數等
都可以指定function的參數來做
在R語言裡面對資料常見的處理都變得很簡單
Rtudio從介面就可以直接檢視資料、視覺化圖、匯入匯出圖
可以寫code操作資料的同時視覺化結果
所以請把Excel關掉換成Rstudio,謝謝
Step 2: 資料前處理
俗話說: 前處理做得好,分析自然好
要做前處理請先觀察資料有什麼內容
例如WSGI這個欄位,我們想看一下到底有哪些類別
在R裡面把它變成factor這種資料型態就可以:

表示有WSGI這個欄位值有gunicorn、gunicorn+meinheld、werkzeug這三種
像這種類別型的資料欄位,我們把他轉為factor資料型態
同樣的道理,把第2欄跟第三欄也變成factor
一樣用: data$欄位名稱 = factor(data$欄位名稱)
$ + 欄位名稱就可以拿出該欄所有值也可以對該欄位值進行覆蓋
類似python裡面用pandas操作的結果
阿如果有100個欄位勒,是不是想用for ? 不要!!!!
R大部分的資料結構都是iterable
(習慣講iterable這個字是因為我母語是java的關係 = = ,算了反正這樣也比較好讓人理解?)
只要用 data[1:100] = lapply(data[1:100], factor)
就可以把前100欄的資料型態轉成factor,超好用吧
1:100表示前100欄的索引
:是連續索引的省略例如1:100就是1到100
如果要表示非連續索引,使用c(1:2,5:6,7) 表示1,2,5,6,7
例如:
column = c(1:2,5:6,7)
data[ column ] = lapply(data[ column ], factor)
就可以將1,2,5,6,7這些欄位全部變成factor型態
這個寫法比python的numpy好寫很多
lapply是R比較潮的寫法,幫你把input的資料每個element丟到function裡面,會回傳list回來
學過python map function的應該很好理解
看不懂就記得lapply可以拿來一次改你的dataframe裡面多個欄位的型態
換別的檔案的時候改dataframe變數和 column 變數就好
因為這是個簡單的dataframe,所以沒有那種很髒的混和型的資料
例如數字文字混合的欄位、空值很多的欄位、沒有類別的欄位(文字欄位)
用Excel處理的話可以用函式+巨集操作資料
(還是要寫code拉,可以用函式處理的資料表示都不夠髒)
R的話有許多強大的資料操作技巧可以做前處理,如果會R你不會想要用Excel操作的
請把Excel關掉換成R,Excel當成一種檔案格式使用就好
下次再分享一下R語言做資料前處理的技巧~~~
我們現在要看的是資料分析~~
阿我們先對資料做點篩選
我今天這個資料是兩個Api的壓測紀錄
我要篩選出search tfidf這支Api的資料列表
從資料表中Request_url這個欄位篩選出值為
'http://search/tfidf?file_name=docs&doc_id=id1'
的資料:
rows = data$Request_url =='/search/tfidf?file_name=docs&doc_id=id1' df = data[ rows ,]
第一行:只要是符合判斷的那幾列,都回傳true
第二行:篩選出符合判斷的資料
不用for迴圈我再說一次,就可以篩選資料列表
Step 3: 資料視覺化
終於輪到ggplot要登場了,在碩班做研究的時候跟這小子混得很熟阿
阿要裝一下ggplot(上面readxl示範過了)
我們有一個處理完的dataframe
這邊分享一下視覺化的重要觀念: 要畫成什麼圖要看我們想分析的資料是什麼型態
如果我們想看以gunicorn 運行服務每秒鐘可以處理的請求數,通常畫柱狀圖(barplot)
因為我們的x軸會是gunicorn,y軸是請求數,所以不會用折線圖
折線圖通常是想看y軸是數字隨x軸是時間變化下的數字變化 (有斜率的,例如雨量變化by days)
ggplot剛開始不會看的時候很gg,所以我們一步一步來畫:
# 首先把你準備好的資料丟進去 ,然後指定x軸跟y軸的欄位,以及用什麼欄位來畫顏色 ggplot( data = df, aes(x= WSGI, y = `Requests per second [#/sec] (mean)` , fill = WSGI)) + geom_bar(stat="identity")
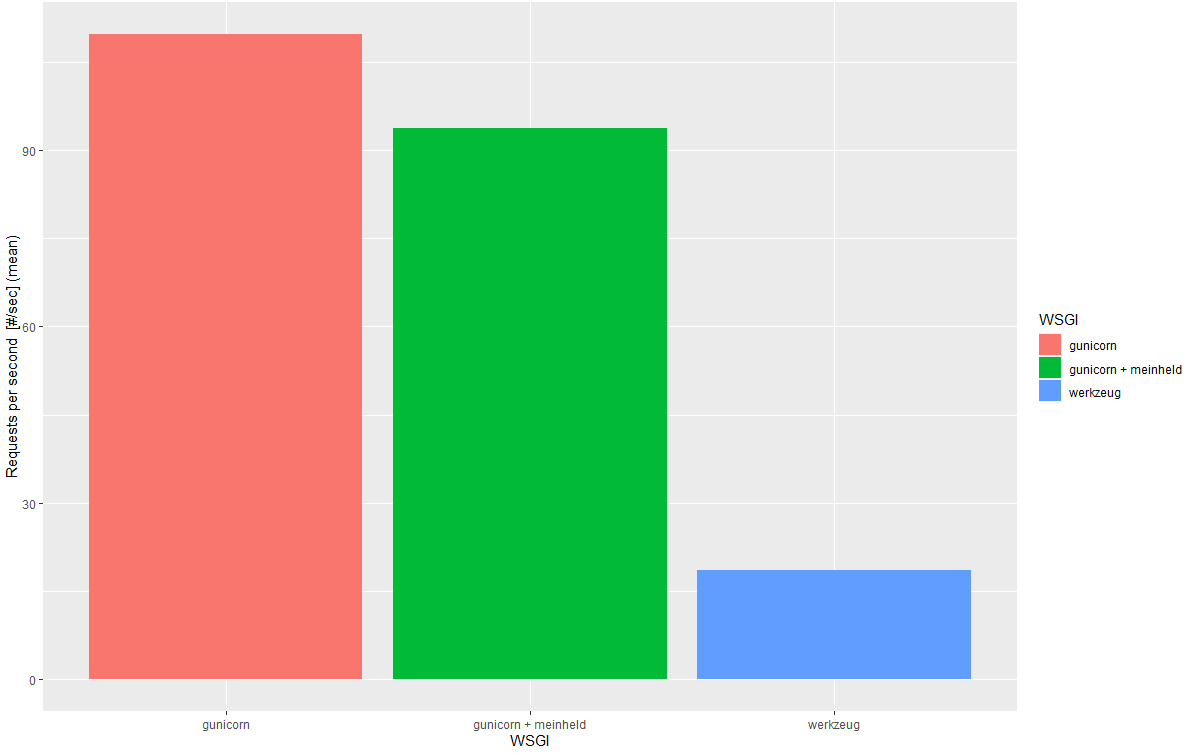
看不出什麼對嗎,沒錯因為應該要把c = 1,2,4分別畫三張柱狀圖出來看才看的出來
但是我不想看三張圖分開!!!!!!
這裡我們使用ggplot的facet_wrap方法,將圖 "拆開" :
ggplot(data =df, aes(x= WSGI, y = `Requests per second [#/sec] (mean)` , fill = WSGI)) + geom_bar(stat="identity")+ facet_wrap( ~ `ab parameters`)
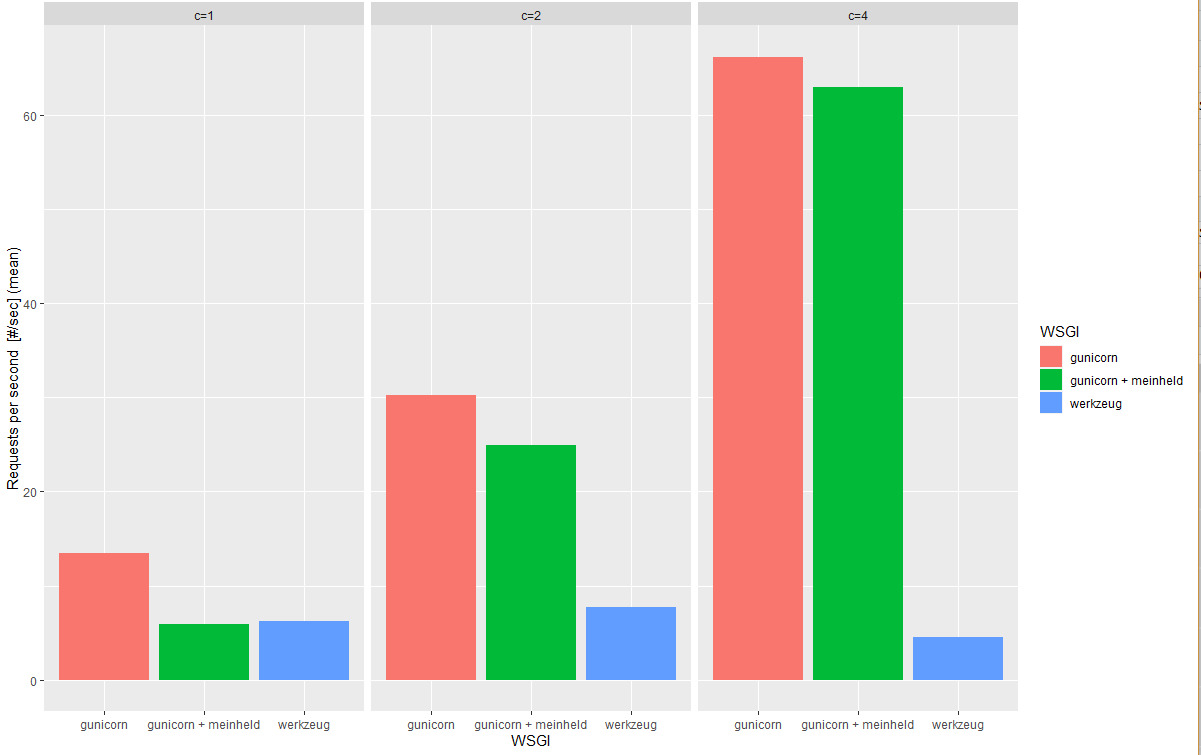
Step 4: 資料分析以及解釋
看出來了吧!
在c= 1的情形下,以werkzeug的伺服器模組啟動服務,每秒鐘可以處理的請求數量只有6.24個,而gunicorn可以處理13.43個
當c= 4時,一次送出4個Api請求,werkzueg每秒鐘可以處理的請求數量不變,而gunicorn可以處理66個!
這表示gunicorn比werkzueg更能夠平行處理Api的請求,在c = 1,2,4得情形下都完勝werkzueg!!!
所以我們可以選擇使用gunicorn做以文找文的伺服器模組,werkzeug原地放生~
ggplot真的很簡單,就是想畫什麼就一直+下去就對了
後面我們做一些客製化把圖的標題寫清楚、調整文字的垂直高度、畫出背景框線
ggplot(data =df, aes(x= WSGI, y = `Requests per second [#/sec] (mean)` , fill = WSGI)) +
geom_bar(stat="identity")+
facet_wrap( ~ `ab parameters`)+
ggtitle("Api:Search tfidf")+
theme(plot.title = element_text(hjust = 0.5))+
geom_text(aes(label= `Requests per second [#/sec] (mean)`), vjust=1.6, color="white", size=3.5)+
labs( x = 'WSGI http server') +
theme(
panel.background = element_rect(fill = "lightblue",
colour = "lightblue",
size = 0.5, linetype = "solid"),
panel.grid.major = element_line(size = 0.5, linetype = 'solid',
colour = "white"),
panel.grid.minor = element_line(size = 0.25, linetype = 'solid',
colour = "white"),
axis.text.x=element_blank()
)
都說是客製化嘛其實code上網查就好,只要對資料視覺化夠熟
其實大學用過javascript的D3.js做專題的網站視覺化
學的時候也是慢慢疊加圖畫,
之後都是改資料欄位名稱就好
有用過的人應該學ggplot會滿快的
但是用R操作資料會快很多
我現在光是想起以前大學用java和excel處理資料就覺得簡直在浪費青春 = =
以上是資料分析常見的動作
全部code也才幾行
#install.packages("readxl")
library("readxl")
data = read_excel("ab_result.xlsx" )
data$WSGI = factor(data$WSGI)
levels(data$WSGI)
data[1:3] = lapply(data[1:3], factor)
levels( data$`ab parameters`) = c( 'c=1' , 'c=2', 'c=4')
#install.packages("ggplot2")
library(ggplot2)
df = data[data$Request_url =='/search/tfidf?file_name=docs&doc_id=id1',]
ggplot(data = df, aes(x= WSGI, y = `Requests per second [#/sec] (mean)` , fill = WSGI)) +
geom_bar(stat="identity")+
facet_wrap( ~ `ab parameters`)+
ggtitle("Api:Search tfidf")+
theme(plot.title = element_text(hjust = 0.5))+
geom_text(aes(label= `Requests per second [#/sec] (mean)`), vjust=1.6, color="white", size=3.5)+
labs( x = 'WSGI http server') +
theme(
panel.background = element_rect(fill = "lightblue",
colour = "lightblue",
size = 0.5, linetype = "solid"),
panel.grid.major = element_line(size = 0.5, linetype = 'solid',
colour = "white"),
panel.grid.minor = element_line(size = 0.25, linetype = 'solid',
colour = "white"),
axis.text.x=element_blank()
)
資料分析步驟都寫成code以後
繼續壓測我的Api新增資料到excel
code都不用動,可以重複使用拉
資料變多以後再丟一次,就有不同的結果
重要的是要有解釋的能力
總結
範例是我自己用ab apache測以文找文Api紀錄結果成excel檔
用R語言做資料視覺化的分析並說明得到的結果
應該要選擇用gunicorn來做服務
小資料看起來很簡單
倘若今天面對的是巨量資料呢?
視覺化工具以及解釋能力就是分析師重要的武器
深深記得我大中山大學管理學術研究中心資料分析大神卓雍然教授
當初對我的資料分析經驗傳授:
"你在做分析的時候,首先將是變數的欄位找出來,觀察你的x及y是什麼型態的資料,再決定以何種視覺化圖呈現。資料分析畫圖要熟且快,你可以一次快速地畫出幾十張圖,只要選擇出一張重要的圖可以說明你的分析結論,能夠良好的解釋讓人明白分析出來的結果,就非常的有價值。我們在做分析時最想要能夠看出有什麼變數可以選擇,因此圖要能夠呈現出不同變數之間的數量差異,我們總是希望能夠透過選擇來做決策。"
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
評論