GSS資安電子報0214期 【Apache Cassandra 效能大揭密:吞吐量、反應能力、容量與成本】
對於像 Apache Cassandra 這樣能處理大量資料工作的系統來說,效能和容量其實就是成本,選擇及設定 Java 虛擬機(JVM)會直接影響成本。而 Azul Platform Prime JVM 則顯著地提升 Apache Cassandra 的效能,進而降低維護 Cassandra 叢集的費用。
我們特此來探討 JVM 的選擇和設定對於 Apache Cassandra 的負載能力有多大影響:也就是不同的 JVM 在相同規模的 Cassandra 叢集能達到怎樣的服務水準,也就是不同的流量下可處理(回應)與損失的流量負荷。
Cassandra 非常適合處理大量資料。在合理範圍內,可以透過增加橫向擴充的節點來調整所需的處理能力。我們可以自由選擇叢集的效能和容量,只要有足夠的節點支援就行。每增加一個節點,都會同時增加叢集的儲存容量和處理能力,但同時也意味著增加運算成本。
服務水平如何影響 Apache Cassandra 成本
節點是構成 Apache Cassandra 叢集的基本元素,而節點的成本則取決於其類型和大小。而一個叢集的成本,則取決於叢集必須使用多少這種節點來執行其任務,以達到可接受的服務水準。例如,一種常見的 Cassandra 工作負載節點類型可能是 AWS c5d.2xlarge(8 vCPU、64GB 記憶體、300GB NVMe SSD),其按需成本為每小時 0.576 美元,由 20 個這樣的節點組成的叢集成本將為每小時 11.52 美元,即每年需花費超過 10 萬美元。
在叢集中實際上需要多少個節點,基本上取決於我們需要負載能力,以及每個節點所提供的可用容量。在可用容量方面,對於達到預期的服務水準至關重要。叢集的整體吞吐量或儲存容量,僅在這個容量保持在預期的叢集服務水準的同時,才能有效地承載負載。叢集的實際配置資源(以及相應的成本)將必然被調整到足以滿足服務水準的要求。
JVM 選擇和配置如何影響 Cassandra 的成本
JVM 的選擇和設定對程式速度和回應時間一致性都有著巨大的影響。JVM、JIT(即時編譯器)和垃圾回收技術的綜合效應可以在 Cassandra 的吞吐量和回應能力中觀察到。能夠在高吞吐量情況下持續保持可靠快速和敏捷的 JVM ,將可以提升 Cassandra 在相同硬體配置下的負載能力,進而降低叢集成本。
至於無法在潛在的最大吞吐量仍然保持預期的回應水準的 JVM 配置,因為使用這種 JVM 無法確保服務能力進而導致應用程式崩潰。為避免這種狀況不可避免地必須“過度配置”的冗余叢集,而無法充分利用每一個節點。
Cassandra 叢集的負載承載能力
要量測特定叢集配置的負載承載能力其實相當簡單,儘管可能會有一些耗時:我們需只要從吞吐量 0 至某個最高吞吐量的流量水平之間,每個流量水平持續一段時間,來驅動叢集,並確定叢集在配置下能夠可靠地維持所述服務水準期望的最高吞吐量。
測試範例
在我們的測試中,我們選擇 Datastax 在測試 Cassandra 4.0 的Benchmark 時使用範例,使用了相同的 tlp-cluster 配置及相同的 TLP 壓力測試工作負載 。
服務水準期望說明
我們假定一個為客戶提供查詢的服務,如果查詢花費的時間超過 100 毫秒,就必須採取替代措施或報錯。我們指定的服務水準期望是(在一個完全配置且預熱的叢集中)在任何給定的 10 秒內,不超過 0.1% 的客戶查詢報錯。也就是這個要求負載測試期間的所有 10 秒內,實際查詢的 99.9% 都保持在 100 毫秒以下。例如,以每秒 10,000 個查詢的查詢速率來看,這相當於在任何 10 秒內最多只會有 100 個超時報錯的期望。
由於需要測量和建模在所有 10 秒內的 99.9% ,我們使用了稍微修改過的 tlp-stress 版本來收集我們的服務水準指標。我們建立了在所有已測試的 JVM 配置下,在不同百分位數水平和不同負載下,客戶實際體驗到的查詢回應時間的模型。
執行時間、預熱時段和重複執行次數
我們決定在每個吞吐量和 JVM 配置下使用一個長達 2 小時的持續負載測試時段,因為早期的測試顯示,測試時間長度不足通常會配置尚未最佳化(尚未完整啟動整體服務)而導致服務水準下降。
為確保測量服務水準是在良好預熱的配置下進行的,我們對每個吞吐水平測試都在一個新配置的叢集上單獨運行,共計 150 分鐘(2.5小時)。每個叢集的生命中的前 30 分鐘被視為預熱時段,而服務水準是在每個執行 120 分鐘後開始評測的。
最後,由於不同次執行之間存在變異性,我們決定在每個配置和負載水平中進行 5 次重複測試。這確保了在特定負載下,預期的服務水準在所有執行中都能得到可靠的數據結果,而不僅僅 1 次執行得到的數據。
JVM 設定
我們比較了五種 Java 11 JVM 設定:
- Azul 的 Prime 11.0.13 JDK(使用 C4 垃圾回收器)
- OpenJDK 11.0.13,使用以下垃圾回收器:
- G1
- CMS
- Shenandoah
- ZGC
我們選擇將 Cassandra 節點的堆積大小設置為 40GB,因為這個堆積大小對於各種 JVM 配置來說,無論是否考慮服務水準,都表現出較高的可實現吞吐量,並且對於那些能夠滿足 100 毫秒服務水準要求的 JVM 配置來說,它還具有較高的負載承載能力。
負載測試細節
我們的測試都使用了類似於上述 Datastax 文章中描述的 tlp-stress 基準測試配置
叢集資訊:
- Cassandra 4.0.1
- 3 node cluster, r5d.2xlarge instances
- 40GB heap
- Replication factor = 3
- Consistency level LOCAL_ONE
負載產生器資訊:
- One c5.2xlarge instance
- 8 threads with rate limiting
- 50 concurrent queries per thread
- 80% writes/20% reads
- 非同步查詢
tlp-stressh 使用的指令如下:
tlp-stress run BasicTimeSeries -d 150m -p 100M -c 50 --pg sequence -t 8 -r 0.2 --rate <desired rate> --populate 200000 --response-time-warmup 30m --csv ./tlp_stress_metrics_1.csv --hdr ./tlp_stress_metrics_1.hdr
所有工作負載都運行了 150 分鐘,並允許在執行過程中呈現負載壓縮。
測試的吞吐量水平
在早期的測試中,我們確定了無論服務水準期望如何,我們所有的配置(讀寫比例 80%寫入/ 20%讀取的工作負載),都無法達到超過每秒 120,000 個操作。有了這個上限,以及輕易配置的公共雲資源,我們繼續進行了多次長時間測試,從 20,000 個操作到 120,000 個操作之間,每次增加 10,000 個操作,測試所有 JVM 配置,並記錄了結果。總計,這些測試代表了共 275 個獨立的叢集運行(5 種 JVM 配置,吞吐量水平在 20K 和 120K 操作之間的 11 個負載水平,每個 5 次執行),每次持續 2.5 小時。
Azul Platform Prime 的 Apache Cassandra 測試結果
實際達到的吞吐量(不考慮服務水準):
雖然不能直接顯示配置在保持服務水準的情況下承載負載的能力,但觀察在不考慮服務水準的情況下,在不同嘗試吞吐量水平下實際達到的吞吐量,也可能是具有意義的資訊。我們在測試的 JVM 配置中發現了以下行為:
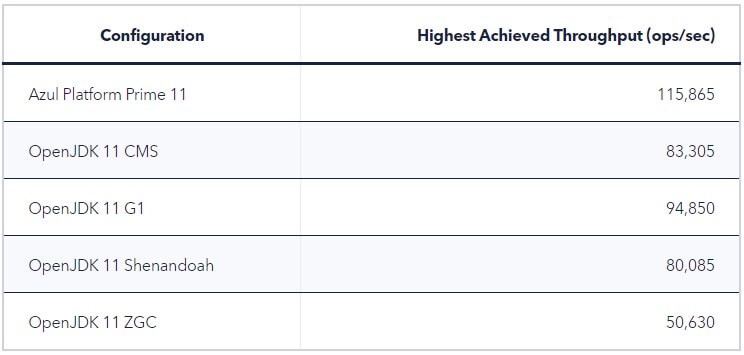
儘管大多數經過測試的 JVM 配置能夠一直保持所要求的吞吐量,一直到它們能夠達到的最高吞吐量,但下面的結果顯示,對於維持所需的服務水準,情況並非如此。
負載承載能力(能夠可靠滿足服務水準要求的最高吞吐量):
正如我們所期望的那樣,在給定配置下增加負載時,會有一個點,該配置的實際服務水準會開始崩潰,並停止滿足要求。這種失敗發生的時間點在 JVM 配置之間變化很大,有些配置甚至在相對較低的負載下就無法滿足所述服務水準,而其他還能續維持服務水準。
至於服務水準,低停頓的垃圾收集器(C4、Shenandoah 和 ZGC)都能夠在巨大的吞吐量下保持所要求的服務水準,但它們可以維持穩定水準的吞吐量差異巨大。下面的圖表和表格詳細介紹了這些結果。
Client-Experienced P99.9 Max on Queries Under Various Loads
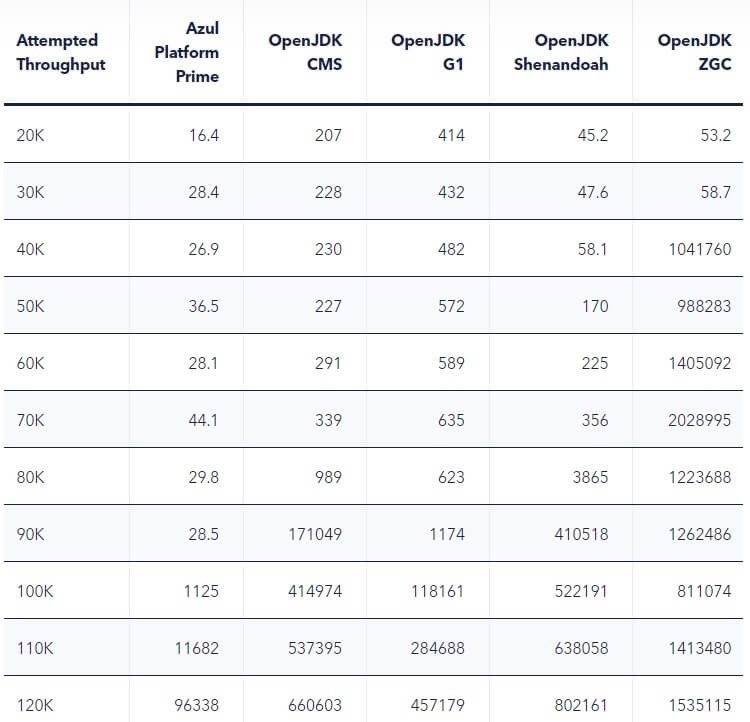
轉換成圖表:
在相同的負載水平下執行的查詢中,我們還提供了客戶實際體驗的 P50 最大值、P90 最大值和 P99 最大值的額外結果,這些結果是在相同一組測試運行期間收集的,可以在這裡找到詳細測試數據。
總結
從這些結果可以看出,Azul 的 Platform Prime JVM 非常快速。單純就吞吐量而言,它無疑是驅動 Cassandra 的吞吐量最高的 JVM 。它還表現出更好的回應時間和延遲,可說是在任何測試下都優於其他 JVM。
但 Azul Platform Prime 真正勝出的是吞吐量和回應性的結合:能夠在接近其最高可達到的吞吐量水平附近還維持良好的回應時間行為,遠遠超過其他 JVM 在相同節點類型上開始失敗服務水準的吞吐量。這種能力使得當 Cassandra 在 Prime JVM 上運行時,可以從每個節點中提取更多有用的容量:在服務水準受損之前,將單個節點的吞吐量和利用率推向更高水平。
在實際應用中,這意味著在處理相同的 Apache Cassandra 工作負載時,需要更少的節點,並且成本更低。成本降低了多少?顯然,這取決於您的 Cassandra 工作負載和服務水準要求。
對於上述的工作負載和服務水準,Azul Platform Prime 展現出的負載承載能力至少比在完全相同的 AWS 實例配置上測試的任何其他 JVM 配置好 2 倍。這意味著成本至少降低了 2 倍。
想了解更多嗎?隨時聯繫我們。我們樂意在您嘗試 Azul Platform Prime 時提供幫助。作為一個替代方案,Azul Platform Prime 可以免費進行測試和評估,通過所謂的 Stream 版本提供。最直接的方法是下載並自行嘗試。請務必參觀 Prime 的 Foojay 社區論壇,向我們提供您所看到的結果。
相關文章
怕被收取高額使用費、資安問題不斷,有沒有好用又有效率的 Java 平台可選擇?
然而,與 Java SDK 相關的安全漏洞層出不窮,再加上即便改用其他 OpenJDK,也會遇上作業系統相容性問題。