當 AI 開始自己做決定 企業風險治理的下一道防線在哪裡?

作者:白佩華
企業在 2026 年面臨的 AI 轉型,已經不再只是「要不要導入生成式 AI」的問題,而是「要不要讓 AI 自己行動」的抉擇。當生成式 AI 從單純回答問題、生成內容,進化成能自主規劃任務、串接系統並執行多步驟行動的 Agentic AI,企業其實已經默默把 AI 從「輔助工具」升級為「具備行動能力的數位員工」。這樣的轉變不僅帶來效率提升,更開啟了一整套全新的風險版圖與治理挑戰。然而,多數董事會與風險管理機制仍停留在「生成式 AI 內容風險」的思維,尚未全面認知到AI已具備行動能力所帶來的治理課題。
風險本質的斷層:內容風險到行動風險,從「說錯話」到「做錯事」
生成式 AI 問世這幾年,大家談得最多的,是「內容風險」:幻覺輸出、偏見、不透明、以及常見的資料外洩與版權爭議等。但至少有一個共同特徵——只要最後一哩路仍由人類決策,錯誤多半會停留在內容層次,尚未直接觸及財務或合約。
Agentic AI 則完全不同,它帶來的是「行動風險」:
- 不只是回錯客服訊息,而是直接寄出錯誤報價。
- 不只是建議調整授信條件,而是實際修改授信額度。
- 不只是彙整競品資訊,而是自行爬取可能涉及版權與個資的資料並寫入決策流程。
錯誤一旦發生,往往是在「被發現之前就已落地」,造成實際的財務損失、法規違反或客戶關係受損,這也是著名的波士頓顧問公司(Boston Consulting Group)所強調的:當 AI 開始「自己行動」時,風險管理已經從資安/模型品質問題,升級為營運連續性與商譽維護的議題。
更關鍵的是「代理鏈」(Agent Chain)的出現:一個負責搜尋資料、一個負責分析、一個負責生成、一個負責觸發執行——任何一環的偏差,都可能經由自動化流程被放大,形成難以追溯的靜默失效(silent failure)。這正好對應麥肯錫(McKinsey)在 AI 信任成熟度模型中新增的「Agentic AI 治理與控制」維度。在最新的 AI 信任成熟度模型裡,特別把這一塊獨立出來,稱為「Agentic AI 治理與控制」,指出要管理的已經不是單一模型,而是一整條行動鏈與背後的風險傳導機制。BCG 則提醒企業:當AI能「單獨行動」,傳統只關注模型準確率與資安的作法,已經遠遠不夠。
|
維度 |
Generative AI(AI Gen) |
Agentic AI(AI Agent / Agentic AI) |
|
核心角色 |
內容生成工具(Text / Image / Code) |
任務執行者(Decision + Action) |
|
風險本質 |
「說錯」的風險 |
「做錯」的風險 |
|
輸出型態 |
建議 / 內容 / 分析 |
指令 / 行動 / 系統操作 |
|
可逆性 |
高(可人工修正) |
低(行動可能不可逆) |
|
主要風險類型 |
幻覺(Hallucination)、偏見(Bias)、內容錯誤 |
錯誤決策(Wrong action)、流程觸發錯誤自動化事故 |
|
失效模式 |
靜默錯誤(內容不正確) |
行動失效(Operational failure) |
|
風險傳播 |
單點(單次輸出) |
鏈式反應(Chain-of-action) |
|
系統影響範圍 |
使用者層級 |
企業系統層級(ERP / CRM / Finance) |
|
攻擊模式 |
Prompt Injection(影響內容) |
Prompt Injection → 行動劫持(更嚴重) |
|
權限風險 |
通常較低(無系統權限) |
高(具備系統操作權限) |
|
監控重點 |
輸出品質(Output QA) |
行為監控(Behavior Monitoring) |
|
治理核心 |
AI Governance(模型治理) |
Agent Governance(行為與決策治理) |
|
關鍵控制點 |
Prompt 管理—人工審核 |
權限控制(RBAC)—行動前驗證— Human-in-the-loop |
|
法遵風險 |
內容誤導 / 著作權 |
錯誤行為責任 / 合約責任 / 金融責任 |
|
財務影響 |
間接(品牌 / 誤導) |
直接(交易錯誤 / 損失 / 索賠) |
|
保險覆蓋性 |
部分由 Cyber / Media liability 涵蓋 |
需AI責任險(E&O / D&O)補強 |
|
董事會關注點 |
內容是否可信? |
AI 是否在「做決策」與「執行行動」? |
(來源:作者以 AI 整理製表)
從 AI Governance 到 Agent Governance:企業該補的三道結構性缺口
若把麥肯錫及 BCG 的框架,與兩篇文章所描繪的台灣企業現況疊合,可以看到企業在 Agentic AI 上至少有三個結構性缺口。
決策授權邊界:哪些項目可以交給 AI,交到什麼程度?
多數企業在導入 Agentic AI 時,對「哪些決策可以交給 AI?哪些不行?」缺乏明確界定,監督節點也沒有制度化設計。這與麥肯錫調查中「多數企業已開始使用 AI,但只有小部分真正重塑流程並設定清楚風險門檻與人工簽核點」的現象相符。
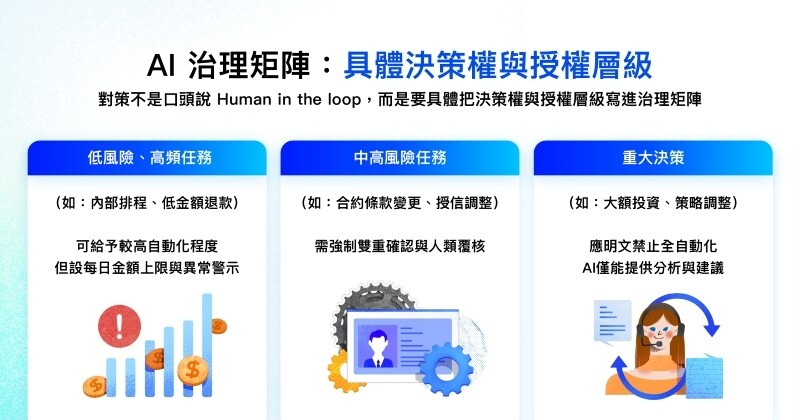
對策不是口頭說 Human in the loop,而是要具體把決策權與授權層級寫進治理矩陣:
- 低風險、高頻任務(如:內部排程、低金額退款)可給予較高自動化程度,但設每日金額上限與異常警示。
- 中高風險任務(如:合約條款變更、授信調整)則需強制雙重確認與人類覆核。
- 重大決策(如:大額投資、策略調整)應明文禁止全自動化,AI 僅能提供分析與建議。
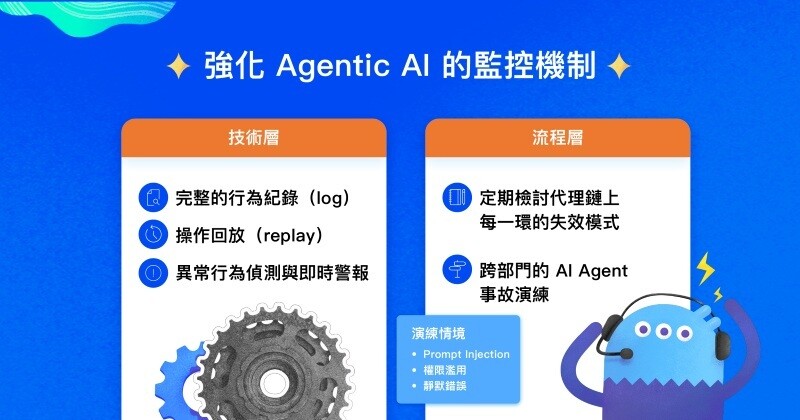
行為與代理鏈監控:你知道 AI「實際做了什麼」嗎?
BCG 與麥肯錫均強調,Agentic AI 的風險來自行為監控不足與缺乏即時可視性。Agentic AI 則必須能夠在 AI 安全與資安架構中監控與具備事件管理能力。回答一個更根本的問題:AI 在過去 24 小時裡做了什麼?這需要在技術與流程上同時補強:
- 技術層:完整的行為紀錄(log)、操作回放(replay)、異常行為偵測與即時警報。
- 流程層:定期檢討代理鏈上每一環的失效模式,以及跨部門的AI Agent事故演練,演練 Prompt Injection、權限濫用與靜默錯誤長期未被發現的情境。
給企業風險管理建議 3 - 2 - 1
若從風險管理顧問的角度,要把國際框架與台灣企業現實對接,以下整理幾個可行的作法: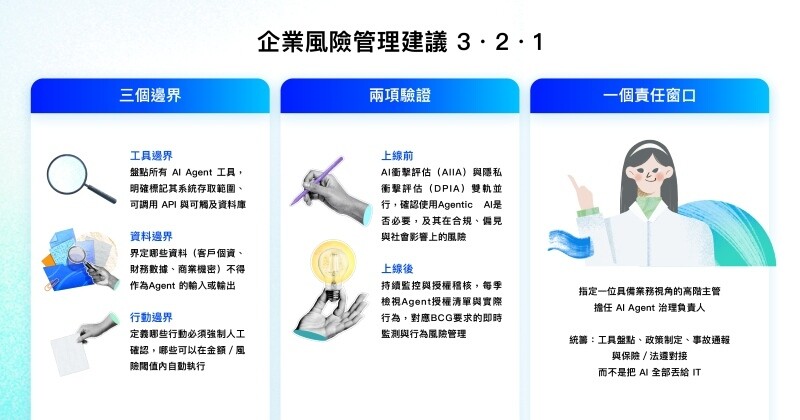
三個邊界
- 工具邊界:盤點所有 AI Agent 工具,明確標記其系統存取範圍、可調用 API 與可觸及資料庫。
- 資料邊界:界定哪些資料(客戶個資、財務數據、商業機密)不得作為 Agent 的輸入或輸出,對應麥肯錫在資料與技術維度的治理要求。
- 行動邊界:定義哪些行動必須強制人工確認,哪些可以在金額/風險閾值內自動執行,呼應 BCG 的「風險分級與自動化層級」設計。
兩項驗證
上線前 AI 衝擊評估(AIIA)與隱私衝擊評估(DPIA)雙軌並行,確認使用Agentic AI是否必要,及其在合規、偏見與社會影響上的風險。
上線後持續監控與授權稽核,每季檢視 Agent 授權清單與實際行為,對應BCG要求的即時監測與行為風險管理。
一個責任窗口
指定一位具備業務視角的高階主管,擔任 AI Agent 治理負責人,統籌:工具盤點、政策制定、事故通報與保險/法遵對接,而不是把 AI 全部丟給 IT。這個角色在國際框架中,通常會位於 AI Steering Committee 或負責任 AI 委員會的樞紐位置,連結董事會風險委員會與營運單位。
真正的競爭力,是「可控的 AI」
未來真正有競爭力的企業,不是最早導入 AI 的,而是最早把 AI 管好。AI 可以越來越自主,但風險不能跟著失控。當 AI 開始自己做決定,企業的真正考題,是能不能負責任地用 AI。
今天起問自己:你能不能拿出一套經得起檢視的 Agentic AI 治理架構?