DeepSeek帶來的AI技術突破與產業影響
就在2025年春節前夕,當大家忙著辦理年貨之際,DeepSeek在全球掀起風暴,規模可謂是繼2022年11月ChatGPT問世後,AI領域最強烈的一次。然而,當時ChatGPT為人們帶來了前所未有全新體驗,而DeepSeek則並未引入嶄新的應用模式,而是在模型訓練或推論技術層面上採取的做法,對業界有深遠影響的成果。
進一步討論前,我們先回顧近年來大語言模型的訓練情況。根據Meta的研究報告,2024年,Meta使用了一個由16,384片NVIDIA H100 GPU組成的計算叢集,耗時54天訓練LLAMA 3.1 405B模型(註1)。考量到每片H100 GPU的價格介於數十萬至百萬新台幣之間,可見訓練成本極為高昂。除了龐大的算力需求,大語言模型的訓練還涉及大量人力與時間,特別是在基於人類回饋的強化學習(RLHF, Reinforcement Learning from Human Feedback)階段,雖然訓練過程中已經透過獎勵模型(RM, Reward Model)部分取代人工評估,以減少逐筆檢查的需求,但RM本身仍需仰賴大量高品質的人工標註數據進行訓練,而這個標註過程仍是一項高度人力密集的工作。因此,一般而言大語言模型的訓練的成本需要上億美元。
因此,DeepSeek特別強調其DeepSeek-V3 671B模型「僅用兩個月時間,使用Nvidia H800 GPU訓練完成,開發成本僅為550萬美元」的說法引起巨大的迴響,因為這意味著其訓練成本僅為OpenAI、Meta等大公司訓練類似模型的二十分之一,卻能達到相當的效果。然而,若仔細閱讀DeepSeek公開的DeepSeek-V3訓練技術文件(註2),可以發現550萬美元的估算是基於租用雲端H800 GPU的假設條件,即每小時2美元,總計278萬GPU小時推算而來。但實際情況是DeepSeek若採用的是自建GPU設備,成本結構就會與雲端租用不同。此外,該估算僅計算了GPU運算時數,並未涵蓋研發、資料處理、測試人力成本,也不可忽略DeepSeek前代 V1、V2等模型所累積下來成果及訓練資料等影響因素。或換句話來說,若現在我們有550萬美元,並照著DeepSeek公布的技術文件進行訓練,是不可能訓練出跟DeepSeek-V3相當的結果。
2024年12月16日,DeepSeek發布了上述的DeepSeek-V3基礎模型,該模型強調的低訓練成本,並採用混合專家模型(MoE, Mixture-of-Experts)架構,在總參數量671B的情況下,每個Token處理時僅啟用其中約37B的參數,大幅提升推理效率並降低硬體資源消耗。憑著訓練與推論階段都擁有的成本優勢,成功吸引了業界目光。而僅僅一個月後,2025年1月20日,DeepSeek進一步發布了DeepSeek-R1推理模型(Reasoning Model),這一版本則是在回答問題時展現出的推理與思考能力讓人驚艷。雖然DeepSeek 並未公布 R1 的具體訓練成本,但從技術文件中可以了解到DeepSeek-R1的訓練極大程度上依賴於DeepSeek-V3。R1的推理能力顯著提升,很大程度上得益於DeepSeek-V3擁有6,710億(671B)的大型參數量,這使得R1在進行大量強化學習(RL, Reinforcement Learning)訓練過程中自行演化出更強的推理能力。因此,若要合理推算 DeepSeek-R1 的訓練成本,必須將 DeepSeek-V3 的訓練成本納入計算,才能得出更貼近實際的成本數據。
但DeepSeek透過不同的訓練策略,使用較低階的GPU設備及較少的訓練時間,就能完成訓練工作也是不爭的事實。深入了解DeepSeek-R1的技術文件指出,在R1的訓練過程中,總共經過了三階段:
- 第一階段:以DeepSeek-V3-Base為基礎,在未採用監督式微調(SFT, Supervised Fine-Tuning)的情況下,直接利用名為Group Relative Policy Optimization (GRPO) 的方式進行RL訓練,訓練出 DeepSeek-R1-Zero,該模型展現了自我驗證與反思等能力,但其生成結果可讀性較低,且會出現語言夾雜(例如中英夾雜)的問題。
- 第二階段:基於第一階段的結果顯示,完全不依賴監督式訓練會影響模型的生成品質,因此,改採用DeepSeek-V3-Base基礎模型及DeepSeek-R1-Zero先產生初始訓練資料(Cold Start Data),其中包括問題、思考鍊(CoT, Chain-of Thought)及答案。這些資料經過人工篩選及整理,組合成高可讀性的高品質資料。接著,以這批Cold Start Data作為學習推理的範例,對DeepSeek-V3-Base進行監督式微調(SFT, Supervised Fine-Tuning)。隨後,利用微調後的DeepSeek-V3-Base及DeepSeek-V3產生共計80萬筆的訓練資料,其中包括「含推理資料(Reasoning data)」及「不含推理資料(Non-Reasoning data)」,作為進一步SFT的訓練資料集。經過再次SFT及RL步驟後,使DeepSeek-V3-Base微調訓練成DeepSeek-R1。
- 第三階段:此階段屬於實驗性質,嘗試透過知識蒸餾(Knowledge Distillation)技術,把訓練完成的DeepSeek-R1作為老師模型,將其推理能力「傳授」給學生模型:如Qwen、Llama等參數量較少的模型(5B, 7B, 8B, 14B, 32B, 70B),經過知識蒸餾的方式,成功賦予小型模型也有推理(Reasoning)能力。
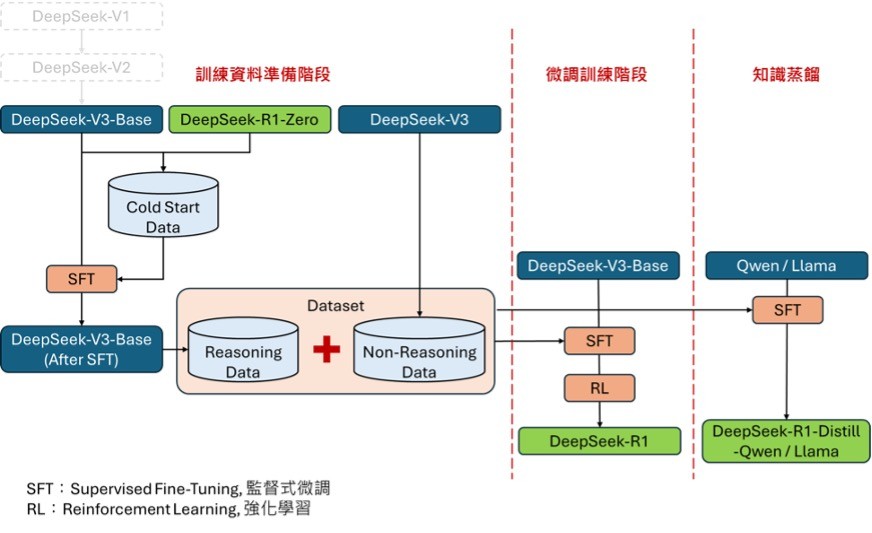
圖1. DeepSeek-R1的訓練第二、第三階段訓練流程
然而,透過知識蒸餾進行模型訓練,並非DeepSeek的獨家技術,叡揚資訊除了在LLM相關的研究計劃持續的在做實驗跟優化,並一直利用SFT(Supervised Fine-Tuning)手法來完成知識蒸餾的步驟。我們更在2024年9月就提出以知識蒸餾作為E2E-VDU(End to End Visual Document Understanding)模型訓練的重要環節,並獲得數位發展部評審的肯定,成功入選113年度「AI領航推動計畫II」。叡揚的E2E-VDU模型主要基於Transformer架構實現的生成式模型為主,籍由融合圖像與文本資訊,以提升對文本影像的理解能力與內容結構的完整性。除知識蒸餾技術以外,我們透過PEFT(Parameter-Efficient Fine-Tuning,參數高效微調)的技術也使模型在因應不同需求時,可以快速進行微調,進而提升模型的適應性與擴展性。同時,為了提升服務可以在有限資源下運行,我們也藉由量化的技術(Model Quantized),實現在資源受限的環境中仍能保有一定的可行性。叡揚資訊選擇此研究方向,主要是因應市場需求與客戶在硬體成本上的壓力,透過該方法,模型參數量可有效縮減80% ~ 90%,使企業能以更少的GPU資源,甚至僅使用CPU,即可享受AI模型帶來的效益,大幅降低運行成本。透過叡揚資訊開發的「 InsAI智慧辨識系統」,企業便可輕鬆運用E2E-VDU模型處理及解析各類文件,例如各類擁有表格、勾選欄位的複雜文件(如申報單、紀錄表…等)、手寫文件(如存款單、手寫收據…等)。系統可自動解析文件並輸出結構化資料,若透過API介接,還能以JSON格式直接與現有系統整合,快速賦予現有流程AI能力,提升自動化處理效率。
我們認為隨著相關技術的成熟,未來AI應用發展可預期將朝以下方向演進:
- 專用小參數語言模型興起:由於成本與效能考量,企業不會單純依賴單一大參數語言模型,而是針對特定應用場景或領域資料,訓練多個小型語言模型,以提升精準度與效率。
- 大語言模型與小語言模型的協同運作:小語言模型可負責特定領域的內容生成,再由大語言模型進行彙整、翻譯或潤飾等高階處理,以提升整體應用的精確度及價值。
- GPU需求將隨著應用持續增加:隨著AI模型在各種應用場景的導入,對於GPU的需求將會從大型的訓練機構轉至各企業內部,遍地開花的結果讓GPU整體需求將不降反增,未來AI 訓練與推論架構將更強調效能與成本的平衡。
因DeepSeek而讓世人得知知識蒸餾技術的廣泛應用,正加速推動AI產業進入更高效率、更低成本的時代,隨著 AI 訓練與推論技術的進一步優化,企業將能更靈活地部署 AI 解決方案,然而多個不同的應用系統使用多個不同的小型語言模型或大語言模型,將引發資訊治理上的挑戰。為解決此問題,於2023年12月叡揚舉辦之AI Solution Day提出 LLM Gateway的概念,以一個LLM為Common agent先判斷問題後,再交由後頭其他小模型之最適者來進行推論,協助企業管理多對多的模型應用關係,此概念立即獲得客戶認同,並於 2024在某部會實作完成,提供以下核心功能:
- 集中管理語言模型:可統一管理地端部署或雲端的語言模型,並對收費的雲端模型進行費用控管。
- 統一規格的 API:讓各應用系統透過與 OpenAI 相容的 API 格式呼叫不同的語言模型。
- 集中的模型權限管理:可設定不同應用系統對不同語言模型的多對多存取權限。
- Prompt記錄與查詢:紀錄每一次的 Prompt,並可依應用系統進行查詢。
- Token量統計與費用預估:紀錄每一次語言模型的輸入與輸出 Token 數,並可對收費模型進行費用預測。
整體而言,隨著AI硬體成本的持續下降,AI應用的普及將進一步加速,企業與個人都能以更低的成本獲取高效率的AI服務。但無論技術如何發展,資訊應用與管理始終是資訊業界的核心本質,未來的挑戰將圍繞如何更有效率地整合與運用這些新一代的技術。
參考資料:
註1 : https://ai.meta.com/research/publications/the-llama-3-herd-of-models/


