GSS 資安電子報 0242 期【案例解析:透過 Claude Opus 4.6 獵捕零日漏洞】
AI 真的能找到 Zero-Day 漏洞嗎?
一個 AI 模型能夠自主找出真實、此前從未公開、存在於正式環境軟體中的安全漏洞。這聽起來是劃時代的突破,「它 真的那麼厲害?」在 Anthropic 發布 Claude Opus 4.6 並展示其發現 zero-day 漏洞能力時,這正是外界的第一反應。
但這件事本身真的有那麼神奇嗎?其實不盡然。
首先,利用大型語言模型(LLM)輔助辨識 zero-day 並不是全新概念。這也不是第一次有人宣稱透過 LLM 工具找到 zero-day 漏洞。早在 2024 年,Google 的 Big Sleep 專案便在 SQLite 中發現 zero-day;研究人員也曾運用 o3 模型揭露 CVE-2025-37899。這些案例其實已存在一段時間。
然而,Opus 4.6 的亮相,確實再次提醒了我們可能真的要好好評估 LLM 的能耐。也藉此讓我們有機會從更宏觀的角度檢視整體趨勢,歸納其模式與優劣,好好看看這些進展對應用程式安全產業與 zero-day 漏洞發掘的長遠意義。
以 AI 進行漏洞獵捕
從市場熱度來看,AppSec 應用程式安全領域正積極擁抱現代 AI 能力,其中也包括以 LLM 為基礎的資安審查。但現實很骨感,我們可能還有很長的一段路要走。
LLM 在特定場景下表現亮眼,但在另一些情境中卻可能出現嚴重誤判。其實現在情況很明瞭:LLM 是一種強而有力的增強型工具,但目前仍無法取代既有的安全工具鏈與成熟流程,例如 SAST、DAST、IaC 掃描工具,以及背後具備判斷力與經驗的資安專家。
可落地執行的資安控管,仰賴的是一致性、可追蹤性、完整覆蓋度與合規性,而這些正是成熟 AppSec 工具長期提供的能力。資安專業人員則將工具產出的結果轉化為組織層級的實際行動,透過專業判斷、驗證機制與責任歸屬,確保相關控制措施得以有效運作與治理。
相較之下,生成式 AI(GenAI)資安工具在提供決定性與可稽核性的安全保證方面仍顯不足,而這正是完整資安架構的核心。
它們真正的優勢其實在於:加速漏洞分級處理、補強情境脈絡,以及提升開發者效率(例如彙整掃描結果、解釋漏洞成因、提出修補建議)。
這些能力,對開發者、資安人員以及所有參與安全軟體交付的團隊而言,都是極具價值的強化工具。
說來有趣,連 Anthropic 自己在其 LLM zero-day 獵捕的部落格文章中,也承認了這點:
「隨著漏洞發現量增加,我們邀請了外部(人類)資安研究人員協助驗證與修補。其目的是協助維護人員處理「我們」的報告,因此流程設計重點要放在降低誤報。
——〈Evaluating and mitigating the growing risk of LLM-discovered 0-days〉」
說真的,我們喜歡與 Anthropic 合作的其中一個原因正是他們對這類透明度的重視,作為研究人員,我們非常欣賞這點。
接下來,我們將更深入分析這代表的意義:拆解 Claude 與其他 LLM 擅長的領域,以及在全面依賴 LLM 作為資安審查工具之前,需要注意的潛在風險與限制。
情境決定一切
這聽起來有說跟沒說一樣但:我們都知道對於 LLM 來說,情境是關鍵。然而,雖然大家都在談 zero-day 漏洞的發現,卻很少再提「情境」的重要性。搞得好像有人有特異功能,可以在長短不一、複雜的程式碼環境(例如真實的生產環境用代碼庫)中,自動找到 zero-day漏洞。事實上:沒有那種事。
如果你懂得如何操作(難的是這個「如果」),Claude等LLM 確實能幫你在「容易處理的部分」節省大量時間。Claude 可以做到在幾秒鐘內審查大量程式碼,辨識已知撰寫模式,並標記明顯不安全的程式碼位置,例如你在什麼地方做了 eval()呼叫。但實務上,情境範圍越廣泛,結果通常越不理想。
但畢竟口說無憑,以下就帶你親身了解 Checkmarx Zero 研究團隊的實際探索歷程。
我們先來看看 Anthropic 所宣稱 Claude Opus 在 CGif 函式庫中找到的一個 zero-day 漏洞。你也可以自行檢視 CGif 函式庫中的 overflow 問題。
檢視這個程式庫後,你會發現實際程式碼僅分布在 3 個不同的 C 檔案(每個約 600 行程式碼)以及 2 個額外的 header 檔案(每個約 100 行程式碼),總計不到 2,000 行程式碼。
那麼,這能代表企業程式碼與真實漏洞嗎?雖然這個實驗性的發現蠻酷的,但它真的符合現實情境嗎?它能涵蓋你的實際使用案例嗎?坦白說,我們也不太確定。
同樣地,自 Opus 4.6 推出以來,Claude Code Security 的功能多半強調它可以幫助降低傳統資安工具的誤報率。但若我們發現在大型程式碼庫中和 Claude說「嘿,找出這兒的漏洞」,許多簡單且知名的漏洞類型常常被漏掉。更糟的是這種方式不僅降低了真正的漏洞偵測率,還會大幅提高誤報率。
舉個要求 Claude 審查整個 n8n 程式庫的實例:
在使用單一題示詞並消耗大約90%的可用token後,產出分析報告共標示出八個漏洞,而在這八個漏洞中,只有兩個是真正的漏洞(true positives)。
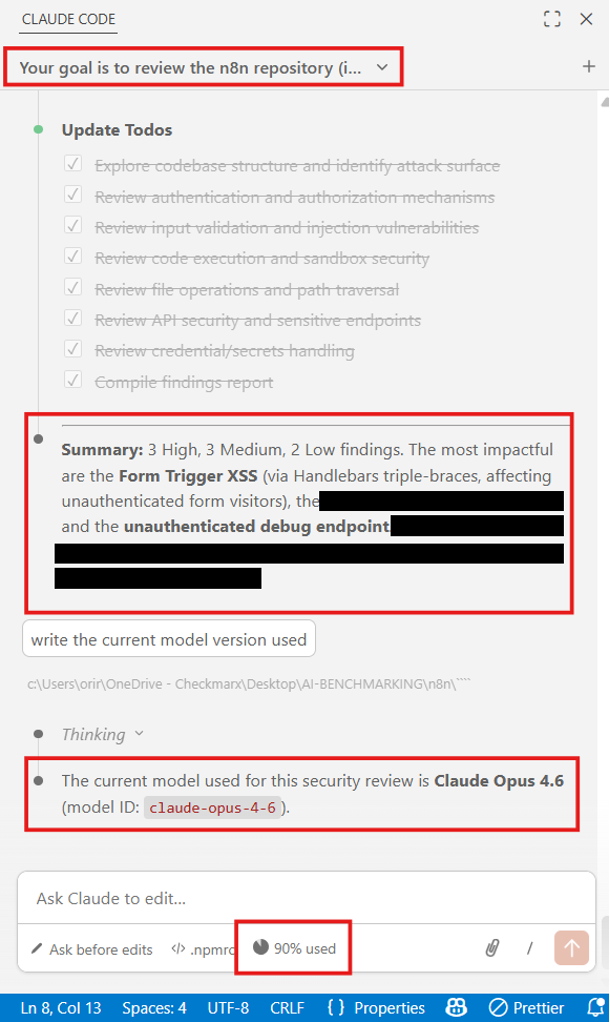
Claude Code Security 分析 n8n 程式庫;具體細節已被遮蔽,因為尚未修補。
結果摘要(部分資訊為簡化已遮蔽):
- Form Trigger XSS 誤報(False Positive):雖然 sink 與input有正確識別,但其中的消毒作法未被識別(如form description、customCss 或 form HTML 的消毒作法)
- 其中提到的Debug模式端點在未登入狀態下預設其實是停用的。
我們的一項測試使用了完整的生產級程式碼庫掃描,除了要求 Claude 搜尋漏洞外並未提供任何特定情境資訊。分析結果標示出八個漏洞,但過程中消耗了大約 90% 的可用 token,整個檢測僅來自單一提示要求。在這八個漏洞中,只有兩個是真正的漏洞(true positives)。
為了提升分析結果精準度,我們嘗試提供更多背景資訊,讓 Claude 專注於特定程式碼,並加入與漏洞相關的資訊,例如過去已知的漏洞案例與寫法。舉例來說,Claude 在開源套件中發現了以下情況:
- 假的 zero-day,真實存在的問題:FreeRDP 的 Null Pointer Dereference
Claude 報告了 FreeRDP SDL2 檔案中的 null-pointer dereference。乍看之下,這個發現值得上報給上游維護者,因此我們進行了報告。不過,我們發現這個漏洞其實已經在原始公告中被披露,而維護者已經在 SDL3 檔案中完成修補。換句話說,Claude 只是重新找到已知漏洞,卻將其誤標為新的 zero-day,沒有辨識或揭露先前的報告。
不過雖然 SDL2 已經被棄用超過一年,FreeRDP 維護者仍針對這個問題做出了回應,並提供了正式的 SDL2修補程式。
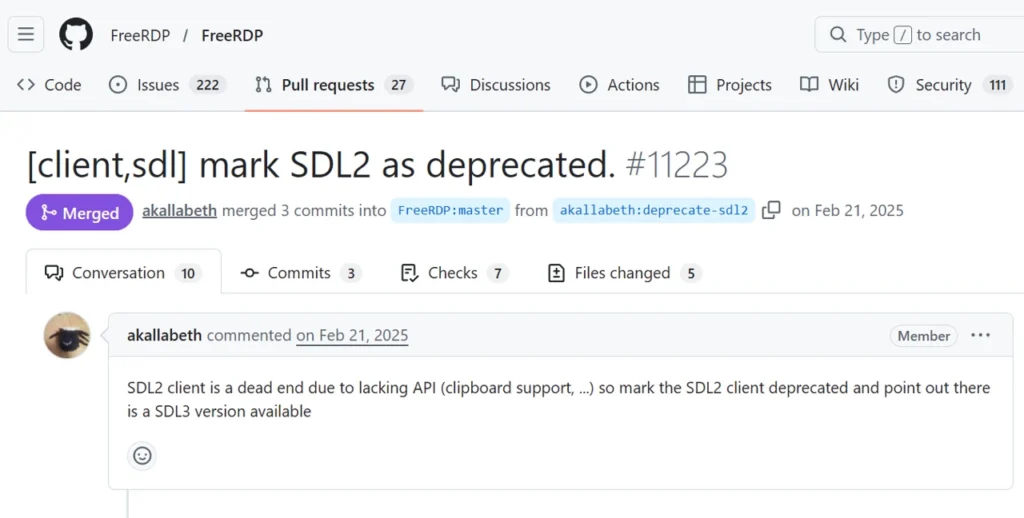
GitHub 註解顯示 FreeRDP 中 SDL2 已被棄用
n8n 中的 SVG XSS 漏洞
Claude Opus 4.6 成功識別了 n8n 中基於 SVG 的漏洞。有趣的是,這個漏洞並非只有 Opus 4.6 能抓到,OpenAI 的模型以及其他 Anthropic 模型也能檢測到。然而,Opus 4.6 也聲稱一旦處理了 SVG,就能完全解決這個問題。但其實並非如此,詳情可以參考關於 MIME type sniffing以及 BlackFan 的 content-type 研究來了解原因。這提醒我們,AI 的建議不能盲信,採取行動前一定要經過專業人員的檢視。
其實呢,我們提出這些觀點並非要批評 Anthropic。事實上,我們非常尊重他們及其產品,這也是我們願意投入研究時間的原因之一。他們打造了一個令人印象深刻的產品,而這款產品在幾年前還只是遙不可及的夢想。然而,前面提到的這些重要細節在公關宣傳或產業KOL的報導中往往未被充分強調,看看 Claude Code Security 發布時的過度反應,就能理解這點。
作為資安公司,我們深知防禦方需要的不僅僅是「漏洞識別」。資安團隊需要判斷結果是否為誤報、漏洞是否可被利用、影響範圍為何、優先處理順序,以及其他相關資訊。這些並非願望清單,而是我們每天從客戶那裡聽到的真實需求。
然而,目前世代的 AI 工具無法以可重複且可靠的方式提供這些答案。如果缺乏足夠的背景資訊(以及使用者需承擔的相關成本支出),其能力將更受限。正如我們前面所說,提供充分背景資訊與前提並非易事。當你開始考量像 n8n 這類專案,要用 LLM 並搭配足夠前情提要進行掃描,其成本可能會讓你在看到任何有意義結果之前,就耗盡 token 配額。
舉例來說,在 n8n 的審查中,我們僅為這一次發現就消耗了大量上下文配額,結果仍有誤報。那如果擴展到企業級規模,那會多麼的可怕?
對應於 AppSec 應用程式安全的意涵
關於 AI 驅動的漏洞審查,市場的熱度算合理,但只能算部分合理。LLM 確實能找到 zero-day 漏洞,它們能偵測傳統工具可能漏掉的問題,理解複雜的程式碼流程,並揭露需要理解應用程式邏輯才能辨識的漏洞,而不只是單純比對模式。此外,它們能順利融入開發者與資安團隊的工作流程。這也是為什麼 Checkmarx 也提供 AI 資安工具,由此帶來實質價值。
然而,AI 資安工具並非萬靈丹。它們仍會漏掉漏洞,可能出現幻覺結果(hallucinate findings),而且效果會因使用方式及提供的背景資訊而大幅不同。
應用程式安全的未來不是「AI 或傳統工具」,而是「AI 加上傳統工具」,由熟悉兩者優勢與限制的資安專業人員來操作。這意味著需要精心挑選工具組合,並將其巧妙地整合進具有安全意識的開發生命週期中,才能加速安全流程、降低軟體風險,同時控制資安成本。那些將 LLM 視為現有資安實踐的強化器而非替代品的組織,將會是最大受益者。
這種依賴了解使用情境的特性帶來重要啟示:想要從 LLM 驅動的資安審查中獲得價值,並不是簡單地把模型指向程式庫然後等待結果。它需要資安專業知識來有效引導模型,了解應該尋找什麼、如何將程式碼庫拆解成可審查單元,以及如何設計提示(prompt)來最大化覆蓋範圍並降低噪音。此外,還必須仔細權衡效益與成本,確保資安計畫在有限預算內仍能運作。
Claude 能否發現漏洞,很大程度上取決於你如何界定審查範圍、提供哪些背景資訊,以及採用哪些方法來引導分析。這是否讓你覺得 Claude 是對現有工具和資安團隊的強力幫手了呢?因為我們是這麼認為的。
善用你的魔法:AI 只是加速器
LLM 在漏洞偵測上的表現越來越出色,這點毋庸置疑。但「令人印象深刻的Demo」與「可投入生產的安全工具」之間,仍存在相當大的差距。背景資訊邏輯的重要性遠比熱潮中大家所認為的還高;發現的結果需要專家驗證;真正的價值在於,將這些AI能力與既有安全計畫、成熟工具以及合格專業人員有策略地整合,而非單純依賴模型本身。
若您對 Checkmarx 有興趣,歡迎於官網中留下資訊,將會有專人與您聯繫 ➤ https://www.gss.com.tw/product-services-nav/info-security/checkmarx-main